Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
Лекции 13,14. Контрастер
Компонент контрастер предназначен для контрастирования нейронных сетей. Первые работы, посвященные контрастированию (скелетонизации) нейронных сетей появились в начале девяностых годов [64, 323, 340]. Однако, задача контрастирования нейронных сетей не являлась центральной, поскольку упрощение сетей может принести реальную пользу только при реализации обученной нейронной сети в виде электронного (оптоэлектронного) устройства. Только в работе А.Н. Горбаня и Е.М. Миркеса «Логически прозрачные нейронные сети» [83] (более полный вариант работы см. [77]), опубликованной в 1995 году задаче контрастирования нейронных сетей был придан самостоятельный смысл – впервые появилась реальная возможность получать новые явные знания из данных. В связи с тем, что контрастирование нейронных сетей не является достаточно развитой ветвью нейроинформатики, стандарт, приведенный в данной главе, является очень общим.
Задачи для контрастера
Из анализа литературы и опыта работы группы НейроКомп можно сформулировать следующие задачи, решаемые с помощью контрастирования нейронных сетей.
- Упрощение архитектуры нейронной сети.
- Уменьшение числа входных сигналов.
- Сведение параметров нейронной сети к небольшому набору выделенных значений.
- Снижение требований к точности входных сигналов.
- Получение явных знаний из данных.
Далее в этом разделе все перечисленные выше задачи рассмотрены более подробно.
Упрощение архитектуры нейронной сети
Стремление к упрощению архитектуры нейронных сетей возникло из попытки ответить на следующие вопрос: «Сколько нейронов нужно использовать и как они должны быть связаны друг с другом?» При ответе на этот вопрос существует две противоположные точки зрения. Одна из них утверждает, что чем больше нейронов использовать, тем более надежная сеть получится. Сторонники этой позиции ссылаются на пример человеческого мозга. Действительно, чем больше нейронов, тем больше число связей между ними, и тем более сложные задачи способна решить нейронная сеть. Кроме того, если использовать заведомо большее число нейронов, чем необходимо для решения задачи, то нейронная сеть точно обучится. Если же начинать с небольшого числа нейронов, то сеть может оказаться неспособной обучиться решению задачи, и весь процесс придется повторять сначала с большим числом нейронов. Эта точка зрения (чем больше – тем лучше) популярна среди разработчиков нейросетевого программного обеспечения. Так, многие из них как одно из основных достоинств своих программ называют возможность использования любого числа нейронов.
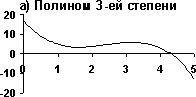
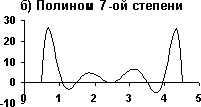 Рис. 1. Аппроксимация табличной функции Рис. 1. Аппроксимация табличной функции |
Вторая точка зрения опирается на такое «эмпирическое» правило: чем больше подгоночных параметров, тем хуже аппроксимация функции в тех областях, где ее значения были заранее неизвестны. С математической точки зрения задачи обучения нейронных сетей сводятся к продолжению функции заданной в конечном числе точек на всю область определения. При таком подходе входные данные сети считаются аргументами функции, а ответ сети – значением функции. На рис. 1 приведен пример аппроксимации табличной функции полиномами 3-й (рис. 1.а) и 7-й (рис. 1.б) степеней. Очевидно, что аппроксимация, полученная с помощью полинома 3-ей степени больше соответствует внутреннему представлению о «правильной» аппроксимации. Несмотря на свою простоту, этот пример достаточно наглядно демонстрирует суть проблемы.
Второй подход определяет нужное число нейронов как минимально необходимое. Основным недостатком является то, что это, минимально необходимое число, заранее неизвестно, а процедура его определения путем постепенного наращивания числа нейронов весьма трудоемка. Опираясь на опыт работы группы НейроКомп в области медицинской диагностики [18, 49 – 52, 73, 91, 92, 161, 162, 166, 183 – 188, 191 – 209, 256, 296 – 299, 317, 318, 344 – 349, 354, 364], космической навигации и психологии можно отметить, что во всех этих задачах ни разу не потребовалось более нескольких десятков нейронов.
Подводя итог анализу двух крайних позиций, можно сказать следующее: сеть с минимальным числом нейронов должна лучше («правильнее», более гладко) аппроксимировать функцию, но выяснение этого минимального числа нейронов требует больших интеллектуальных затрат и экспериментов по обучению сетей. Если число нейронов избыточно, то можно получить результат с первой попытки, но существует риск построить «плохую» аппроксимацию. Истина, как всегда бывает в таких случаях, лежит посередине: нужно выбирать число нейронов большим, чем необходимо, но не намного. Это можно осуществить путем удвоения числа нейронов в сети после каждой неудачной попытки обучения. Наиболее надежным способом оценки минимального числа нейронов является использование процедуры контрастирования. Кроме того, процедура контрастирования позволяет ответить и на второй вопрос: какова должна быть структура сети.
Как уже отмечалось ранее, основная сложность в аппаратной реализации нейронных сетей – большое число связей между элементами. В связи с этим, задача уменьшения числа связей (упрощения архитектуры нейронной сети) приобретает особенную важность. Во многих приложениях, выполненных группой НейроКомп [18, 49 – 52, 65, 73, 91, 92, 161, 162, 166, 183 – 188, 191 – 209, 256, 286, 296 – 299, 300–302, 317, 318, 344 – 348, 354, 364, 367] в ходе процедуры контрастирования число связей уменьшалось в 5-10 раз. Кроме того, при этом уменьшалось общее число элементов. Такое кардинальное упрощение архитектуры нейронной сети резко упрощает ее аппаратную реализацию.
Уменьшение числа входных сигналов
При постановке задачи для нейронной сети не всегда удается точно определить сколько и каких входных данных нужно подавать на вход. В случае недостатка данных сеть не сможет обучиться решению задачи. Однако гораздо чаще на вход сети подается избыточный набор входных параметров. Например, при обучении сети постановке диагноза в задачах медицинской диагностики на вход сети подаются все данные, необходимые для постановки диагноза в соответствии с существующими методиками. Следует учесть, что стандартные методики постановки диагнозов разрабатываются для использования на большой территории (например, на территории России). Как правило, при диагностике заболеваний населения какого-нибудь небольшого региона (например города) можно обойтись меньшим набором исходных данных. Причем этот усеченный набор будет варьироваться от одного малого региона к другому. Требуется определить, какие данные необходимы для решения конкретной задачи, поставленной для нейронной сети. Кроме того, в ходе решения этой задачи определяются значимости входных сигналов. Следует заметить, что умение определять значимость входных сигналов представляет самостоятельную ценность.
Сведение параметров нейронной сети к выделенным значениям
При обучении нейронных сетей на универсальных компьютерах параметры сети являются действительными числами из заданного диапазона. При аппаратной реализации нейронной сети не всегда возможно реализовать веса связей с высокой точностью (в компьютерном представлении действительных чисел хранятся первые 6-7 цифр мантиссы). Опыт показывает, что в обученной сети веса многих синапсов можно изменять в довольно широком диапазоне (до полуширины интервала изменения веса) не изменяя качество решения сетью поставленной перед ней задачи. Исходя из этого, умение решать задачу замены значений параметров сети на значения из заданного набора приобретает важный практический смысл.
Снижение требований к точности входных сигналов
При обработке экспериментальных данных полезно знать, что измерение с высокой точностью, как правило, дороже измерения с низкой точностью. Причем достаточно часто получение очередной значащей цифры измеряемого параметра стоит на несколько порядков дороже. В связи с этим задача снижения требований к точности измерения входных параметров сети приобретает смысл.
Получение явных знаний из данных
Одной из главных загадок мышления является то, как из совокупности данных об объекте, появляется знание о нем. До недавнего времени наибольшим достижением в области искусственного интеллекта являлось либо воспроизведение логики человека-эксперта (классические экспертные системы), либо построение регрессионных зависимостей и определение степени зависимости одних параметров от других.
С другой стороны, одним из основных недостатков нейронных сетей, с точки зрения многих пользователей, является то, что нейронная сеть решает задачу, но не может рассказать как. Иными словами из обученной нейронной сети нельзя извлечь алгоритм решения задачи. Таким образом нейронные сети позволяют получать неявные знания из данных.
В домашнем задании I Всесоюзной олимпиады по нейрокомпьютингу, проходившей в мае 1991 года в городе Омске, в исследовательской задаче участникам было предложено определить, как нейронная сеть решает задачу распознавания пяти первых букв латинского алфавита (полный текст задания и наиболее интересные варианты решения приведены в [47]). Это была первая попытка извлечения алгоритма решения задачи из обученной нейронной сети.
В 1995 году была сформулирована идея логически прозрачных сетей, то есть сетей на основе структуры которых можно построить вербальное описание алгоритма получения ответа. Это достигается при помощи специальным образом построенной процедуры контрастирования.
Построение логически прозрачных сетей

Рис. 2. Набор минимальных сетей для решения задачи о предсказании результатов выборов президента США. В рисунке использованы следующие обозначения: буквы «П» и «О» – обозначают вид ответа, выдаваемый нейроном: «П» – положительный сигнал означает победу правящей партии, а отрицательный – оппозиционной; «О» – положительный сигнал означает победу оппозиционной партии, а отрицательный – правящей;
 |
Зададимся классом сетей, которые будем считать логически прозрачными (то есть такими, которые решают задачу понятным для нас способом, для которого легко сформулировать словесное описания в виде явного алгоритма). Например потребуем, чтобы все нейроны имели не более трех входных сигналов.
Зададимся нейронной сетью у которой все входные сигналы подаются на все нейроны входного слоя, а все нейроны каждого следующего слоя принимают выходные сигналы всех нейронов предыдущего слоя. Обучим сеть безошибочному решению задачи.
После этого будем производить контрастирование в несколько этапов. На первом этапе будем удалять только входные связи нейронов входного слоя. Если после этого у некоторых нейронов осталось больше трех входных сигналов, то увеличим число входных нейронов. Затем аналогичную процедуру выполним поочередно для всех остальных слоев. После завершения описанной процедуры будет получена логически прозрачная сеть. Можно произвести дополнительное контрастирование сети, чтобы получить минимальную сеть. На рис. 2 приведены восемь минимальных сетей. Если под логически прозрачными сетями понимать сети, у которых каждый нейрон имеет не более трех входов, то все сети кроме пятой и седьмой являются логически прозрачными. Пятая и седьмая сети демонстрируют тот факт, что минимальность сети не влечет за собой логической прозрачности.
Получение явных знаний
После получения логически прозрачной нейронной сети наступает этап построения вербального описания. Принцип построения вербального описания достаточно прост. Используемая терминология заимствована из медицины. Входные сигналы будем называть симптомами. Выходные сигналы нейронов первого слоя – синдромами первого уровня. Очевидно, что синдромы первого уровня строятся из симптомов. Выходные сигналы нейронов k-о слоя будем называть синдромами k-о уровня. Синдромы k-о первого уровня строятся из симптомов и синдромов более низких уровней. Синдром последнего уровня является ответом.
В качестве примера приведем интерпретацию алгоритма рассуждений, полученного по второй сети приведенной на рис. 2. Постановка задачи: по ответам на 12 вопросов необходимо предсказать победу правящей или оппозиционной партии на выборах Президента США. Ниже приведен список вопросов.
- Правящая партия была у власти более одного срока?
- Правящая партия получила больше 50% голосов на прошлых выборах?
- В год выборов была активна третья партия?
- Была серьезная конкуренция при выдвижении от правящей партии?
- Кандидат от правящей партии был президентом в год выборов?
- Год выборов был временем спада или депрессии?
- Был ли рост среднего национального валового продукта на душу населения больше 2.1%?
- Произвел ли правящий президент существенные изменения в политике?
- Во время правления были существенные социальные волнения?
- Администрация правящей партии виновна в серьезной ошибке или скандале?
- Кандидат от правящей партии – национальный герой?
- Кандидат от оппозиционной партии – национальный герой?
Ответы на вопросы описывают ситуацию на момент, предшествующий выборам. Ответы кодировались следующим образом: «да» – единица, «нет» – минус единица. Отрицательный сигнал на выходе сети интерпретируется как предсказание победы правящей партии. В противном случае, ответом считается победа оппозиционной партии. Все нейроны реализовывали пороговую функцию, равную 1, если алгебраическая сумма входных сигналов нейрона больше либо равна 0, и -1 при сумме меньшей 0.
Проведем поэтапно построение вербального описания второй сети, приведенной на рис. 2. После автоматического построения вербального описания получим текст, приведенный на рис. 3. Заменим все симптомы на тексты соответствующих вопросов. Заменим формулировку восьмого вопроса на обратную. Подставим вместо Синдром1_Уровня2 название ответа сети при выходном сигнале 1. Текст, полученный в результате этих преобразований приведен на рис. 4.
Синдром1_Уровня1 равен 1, если выражение Симптом4 + Симптом6 - Симптом 8 больше либо равно нулю, и -1 - в противном случае.
Синдром2_Уровня1 равен 1, если выражение Симптом3 + Симптом4 + Симптом9 больше либо равно нулю, и -1 - в противном случае.
Синдром1_Уровня2 равен 1, если выражение Синдром1_Уровня1 + Синдром2_Уровня1 больше либо равно нулю, и -1 - в противном случае. Рис. 3. Автоматически построенное вербальное описание |
Синдром1_Уровня1 равен 1, если выражение <Была серьезная конкуренция при выдвижении от правящей партии?> + <Год выборов был временем спада или депрессии?> + <Правящий президент не произвел существенных изменений в политике?> больше либо равно нулю, и -1 - в противном случае.
Синдром2_Уровня1 равен 1, если выражение <В год выборов была активна третья партия?> + <Была серьезная конкуренция при выдвижении от правящей партии?> + <Во время правления были существенные социальные волнения?> больше либо равно нулю, и -1 - в противном случае.
Оппозиционная партия победит, если выражение Синдром1_Уровня1 + Синдром2_Уровня1 больше либо равно нулю. Рис. 4. Вербальное описание после элементарных преобразований |
Заметим, что все три вопроса, ответы на которые формируют Синдром1_Уровня1, относятся к оценке качества правления действующего президента. Поскольку положительный ответ на любой из этих вопросов характеризует недостатки правления, то этот синдром можно назвать синдромом плохой политики. Аналогично, три вопроса, ответы на которые формируют Синдром2_Уровня1, относятся к характеристике политической стабильности. Этот синдром назовем синдромом политической нестабильности.
Тот факт, что оба синдрома первого уровня принимают значение 1, если истинны ответы хотя бы на два из трех вопросов, позволяет избавиться от математических действий с ответами на вопросы. Окончательный ответ может быть истинным только если оба синдрома имеют значение –1.
Используя приведенные соображения, получаем окончательный текст решения задачи о предсказании результатов выборов президента США, приведенный на рис. 5.
Правление плохое, если верны хотя бы два из следующих высказываний: «Была серьезная конкуренция при выдвижении от правящей партии», «Год выборов был временем спада или депрессии», «Правящий президент не произвел существенных изменений в политике».
Ситуация политически нестабильна, если верны хотя бы два из следующих высказываний: «В год выборов была активна третья партия», «Была серьезная конкуренция при выдвижении от правящей партии», «Во время правления были существенные социальные волнения».
Оппозиционная партия победит, если правление плохое или ситуация политически нестабильна. Рис. 5. Окончательный вариант вербального описания |
Таким образом, использовав идею логически прозрачных нейронных сетей и минимальные интеллектуальные затраты на этапе доводки вербального описания, был получен текст решения задачи. Причем процедура получения логически прозрачных нейронных сетей сама отобрала значимые признаки, сама привела сеть к нужному виду. Далее элементарная программа построила по структуре сети вербальное описание.
На рис. 2 приведены структуры шести логически прозрачных нейронных сетей, решающих задачу о предсказании результатов выборов президента США [300 – 302]. Все сети, приведенные на этом рисунке минимальны в том смысле, что из них нельзя удалить ни одной связи так, чтобы сеть могла обучиться правильно решать задачу. По числу нейронов минимальна пятая сеть.
Заметим, что все попытки авторов обучить нейронные сети со структурами, изображенными на рис. 2, и случайно сгенерированными начальными весами связей закончились провалом. Все сети, приведенные на рис. 2, были получены из существенно больших сетей с помощью процедуры контрастирования. Сети 1, 2, 3 и 4 были получены из трехслойных сетей с десятью нейронами во входном и скрытом слоях. Сети 5, 6, 7 и 8 были получены из двухслойных сетей с десятью нейронами во входном слое. Легко заметить, что в сетях 2, 3, 4 и 5 изменилось не только число нейронов в слоях, но и число слоев. Кроме того, почти все веса связей во всех восьми сетях равны либо 1, либо -1.
Множества повышенной надежности
Алгоритмы контрастирования, рассматриваемые в данной главе, позволяют выделить минимально необходимое множество входных сигналов. Использование минимального набора входных сигналов позволяет более экономично организовать работу нейркомпьютера. Однако у минимального множества есть свои недостатки. Поскольку множество минимально, то информация, несомая одним из сигналов, как правило не подкрепляется другими входными сигналами. Это приводит к тому, что при ошибке в одном входном сигнале сеть ошибается с большой степенью вероятности. При избыточном наборе входных сигналов этого как правило не происходит, поскольку информация каждого сигнала подкрепляется (дублируется) другими сигналами.
Таким образом возникает противоречие – использование исходного избыточного множества сигналов неэкономично, а использование минимального набора сигналов приводит к повышению риска ошибок. В этой ситуации правильным является компромиссное решение – необходимо найти такое минимальное множество, в котором вся информация дублируется. В данном разделе рассматриваются методы построения таких множеств, повышенной надежности. Кроме того, построение дублей второго рода позволяет установить какие из входных сигналов не имеют дублей в исходном множестве сигналов. Попадание такого «уникального» сигнала в минимальное множество является сигналом о том, что при использовании нейронной сети для решения данной задачи следует внимательно следить за правильностью значения этого сигнала.
Формальная постановка задачи
Пусть дана таблица данных, содержащая N записей, каждая из которых содержит M+1 поле. Обозначим значение i-о поля j-й записи через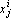 , где , где 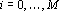 , , 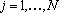 . Обозначим через . Обозначим через 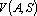 задачник, в котором ответы заданы в полях с номерами задачник, в котором ответы заданы в полях с номерами 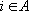 , а входные данные содржатся в полях с номерами , а входные данные содржатся в полях с номерами 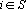 . Множество А будем называть множеством ответов, а множество S – множеством входных данных. Минимальное множество входных сигналов, полученное при обучении сети на задачнике , обозначим через . Множество А будем называть множеством ответов, а множество S – множеством входных данных. Минимальное множество входных сигналов, полученное при обучении сети на задачнике , обозначим через 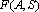 . В случае, когда сеть не удалось обучить решению задачи будем считать, что . В случае, когда сеть не удалось обучить решению задачи будем считать, что 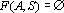 . Число элементов в множестве A будем обозначать через . Число элементов в множестве A будем обозначать через 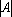 . Через . Через 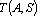 будем обозначать сеть, обученную решать задачу предсказания всех полей (ответов), номера которых содержатся в множестве A, на основе входных сигналов, номера которых содержатся в множестве S. будем обозначать сеть, обученную решать задачу предсказания всех полей (ответов), номера которых содержатся в множестве A, на основе входных сигналов, номера которых содержатся в множестве S.
Задача. Необходимо построить набор входных параметров, который позволяет надежно решать задачу 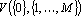 . .
Решение задачи будем называть множеством повышенной надежности, и обозачать 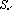 . .
Для решения этой задачи необходимо определит набор параметров, дублирующих минимальный набор  . Возможно несколько подходов к определению дублирующего набора. В следующих разделах рассмотрены некоторые из них. . Возможно несколько подходов к определению дублирующего набора. В следующих разделах рассмотрены некоторые из них.
Классификация дублей
Возможно два типа дублей – набор входных сигналов, способный заменить определенный входной сигнал или множество сигналов при получении ответа первоначальной задачи, и набор входных сигналов, позволяющий вычислить дублируемый сигнал (множество дублируемых сигналов). Дубли первого типа будем называть прямыми, а дубли второго типа – косвенными.
Возможна другая классификация, не зависящая от ранее рассмотренной. Дубли первого и второго рода будем различать по объекту дублирования. Дубль первого рода дублирует все множество вцелом, а дубль второго рода дублирует конкретный сигнал.
Очевидно, что возможны все четыре варианта дублей: прямой первого рода,косвенный первого рода, прямой второго рода и косвенный второго рода. В следующих разделах будут описаны алгоритмы получения дублей всех вышеперечисленных видов.
Прямой дубль первого рода
Для нахождения прямого дубля первого рода требуется найти такое множество сигналов D что существует сеть 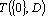 и и 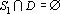 . Решение этой задачи очевидно. Удаим из множества входных сигналов те их них, которые вошли в первоначальное минимальное множество входных сигналов . Решение этой задачи очевидно. Удаим из множества входных сигналов те их них, которые вошли в первоначальное минимальное множество входных сигналов 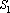 . Найдем минимальное множествовходных сигналов среди оставшихся. Найденное множество и будет искомым дублем. . Найдем минимальное множествовходных сигналов среди оставшихся. Найденное множество и будет искомым дублем.
Формально описанную выше процедуру можно записать следующей формулой:
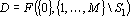 . .
Множество повышенной надежности в этом случае можно записать в следующем виде:
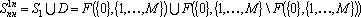 . .
Очевидно, что последнюю формулу можно обобщить, исключив из первоначального множества входных сигналов найденное ранее множество повышенной надежности и попытавшись найти минимальное множество среди оставшихся входных сигналов. С другой стороны, для многих нейросетевых задач прямых дублей первого рода не существует. Примером может служить одна из классических тестовых задач – задача о предсказании результатов выборов президента США.
Косвенный дубль первого рода
Для нахождения косвенного дубля первого рода необходимо найти такое множество входных сигналов D что существует сеть 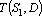 и . Другими словами, среди множества входных сигналов, не включающем начальное минимальное множество, нужно найти такие входные сигналы, по которым можно восстановит значения входных сигналов начального минимального множества. Формально описанную выше процедуру можно записать следующей формулой: и . Другими словами, среди множества входных сигналов, не включающем начальное минимальное множество, нужно найти такие входные сигналы, по которым можно восстановит значения входных сигналов начального минимального множества. Формально описанную выше процедуру можно записать следующей формулой:
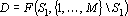 . .
Множество повышенной надежности в этом случае можно записать в следующем виде:
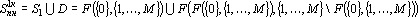
Эта формула так же допускает обобщение. Однако, следует заметить, что косвенные дубли первого рода встречаются еще реже чем прямые дубли первого рода. Соотношение между косвенным и прямым дублем первого рода описываются следующей теоремой.
Теорема 1. Если множество D является косвенным дублем первого рода, то оно является и прямым дублем первого рода.
Доказательство. Построим нейронную сеть, состоящую из последовательно соединенных сетей и  , как показано на рис. 6. Очевидно, что на выходе первой сети будут получены те сигналы, которые, будучи поданы на вход второй сети, приведут к получению на выходе второй сети правильного ответа. Таким образом сеть, полученная в результате объединения двух сетей и , является сетью . Что и требовалось доказать. , как показано на рис. 6. Очевидно, что на выходе первой сети будут получены те сигналы, которые, будучи поданы на вход второй сети, приведут к получению на выходе второй сети правильного ответа. Таким образом сеть, полученная в результате объединения двух сетей и , является сетью . Что и требовалось доказать.
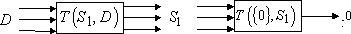
Рис. 6. Сеть для получения ответа из косвенного дубля. |
Следствие. Если у множества 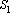 нет прямого дубля первого рода, то у нее нет и косвенного дубля первого рода нет прямого дубля первого рода, то у нее нет и косвенного дубля первого рода
Доказательство. Пусть это не так. Тогда существует косвенный дубль первого рода. Но по теореме 1 он является и прямым дублем первого рода, что противоречит условию теоремы. Полученное противоречие доказывает следствие.
Прямой дубль второго рода
Перенумеруем входные сигналы из множества 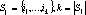 . Множество сигналов, являющееся прямым дублем второго рода для сигнала . Множество сигналов, являющееся прямым дублем второго рода для сигнала 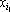 можно получить найдя минимальное множество для получения ответа, если из исходного множества входных сигналов исключен сигнал . Таким образом прямые дубли второго рода получаются следующим образом: можно получить найдя минимальное множество для получения ответа, если из исходного множества входных сигналов исключен сигнал . Таким образом прямые дубли второго рода получаются следующим образом:
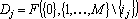 . .
Полный прямой дубль второго рода получается объединением всех дублей для отдельных сигналов 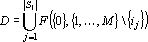 . Множество повышенной надежности для прямого дубля второго рода можно записать в следующем виде: . Множество повышенной надежности для прямого дубля второго рода можно записать в следующем виде:
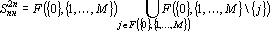
Заметим, что при построении прямого дубля второго рода не требовалось отсутствия в нем всех элементов множества 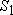 , как это было при построении прямого дубля первого рода. Такое снижение требований приводит к тому, что прямые дубли второго рода встречаются чаще, чем прямые дубли первого рода. Более того, прямой дубль первого рода очевидно является прямым дублем второго рода. Более точное соотношение между прямыми дублями первого и второго родов дает следующая теорема. , как это было при построении прямого дубля первого рода. Такое снижение требований приводит к тому, что прямые дубли второго рода встречаются чаще, чем прямые дубли первого рода. Более того, прямой дубль первого рода очевидно является прямым дублем второго рода. Более точное соотношение между прямыми дублями первого и второго родов дает следующая теорема.
Теорема 2. Полный прямой дубль второго рода является прямым дублем первого рода тогда, и только тогда, когда
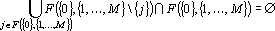 . . |
(1) |
Доказательство. Построим сеть, состоящую из параллельно работающих сетей, 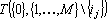 , за которыми следует элемент, выдающтй на выход среднее арифметическое своих входов. Такая сеть очевидно будет решать задачу, а в силу соотношения (1) она будет сетью , за которыми следует элемент, выдающтй на выход среднее арифметическое своих входов. Такая сеть очевидно будет решать задачу, а в силу соотношения (1) она будет сетью 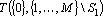 . Таким образом, если соотношение (1) верно, то прямой дубль второго рода является прямым дублем первого рода. Необходимость следует непосредственно из определения прямого дубля первого рода. . Таким образом, если соотношение (1) верно, то прямой дубль второго рода является прямым дублем первого рода. Необходимость следует непосредственно из определения прямого дубля первого рода.
Косвенный дубль второго рода
Косвенный дубль второго рода для сигнала 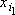 является минимальным множеством входных сигналов, для которых существует сеть является минимальным множеством входных сигналов, для которых существует сеть 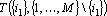 . Полный косвенный дубль второго рода строится как объединение косвенных дублей второго рода для всех сигналов первоначального минимального множества: . Полный косвенный дубль второго рода строится как объединение косвенных дублей второго рода для всех сигналов первоначального минимального множества:
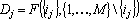 . .
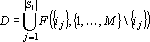
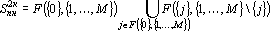
Соотношения между косвенными дублями второго рода и другими видами дублей первого и второго рода задаются теоремами 1, 2 и следующими двумя теоремами.
Теорема 3. Косвенный дубль второго рода всегда является прямым дублем второго рода.
Доказательство данной теоремы полностью аналогично доказательству теоремы 1.
Теорема 4. Полный косвенный дубль второго рода является косвенным дублем первого рода тогда, и только тогда, когда верно соотношение
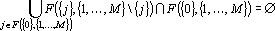
Доказателство данной теоремы полностью аналогично доказательству теоремы 2.
Косвенный супердубль
Последним рассматриваемым в данной работе видом дубля является косвенный супердубль. Косвенным супердублем будем называть минимальное множество входных сигналов, которое позволяет восстановит все входные сигналы. Косвенный супердубль формально описывается следующей формулой:
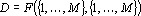
Очевидно, что косвенный супердубль является полным косвенным дублем второго рода. Также очевидно, что косвенный супердубль встречается гораздо реже, чем наиболее редкий из ранее рассматриваемых косвенный дубль первого рода.
Процедура контрастирования
Существует два типа процедуры контрастирования – контрастирование по значимости параметров и не ухудшающее контрастирование. В данном разделе описаны оба типа процедуры контрастирования.
Контрастирование на основе показателей значимости
С помощью этой процедуры можно контрастировать, как входные сигналы, так и параметры сети. Далее в данном разделе будем предполагать, что контрастируются параметры сети. При контрастировании входных сигналов процедура остается той же, но вместо показателей значимости параметров сети используются показатели значимости входных сигналов. Обозначим через 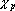 – показатель значимости p-о параметра; через – показатель значимости p-о параметра; через 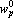 – текущее значение p-о параметра; через – текущее значение p-о параметра; через 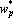 – ближайшее выделенное значение для p-о параметра. – ближайшее выделенное значение для p-о параметра.
Используя введенные обозначения процедуру контрастирования можно записать следующим образом:
- Вычисляем показатели значимости.
- Находим минимальный среди показателей значимости –
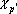 . .
- Заменим соответствующий этому показателю значимости параметр
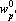 на на 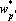 , и исключаем его из процедуры обучения. , и исключаем его из процедуры обучения.
- Предъявим сети все примеры обучающего множества. Если сеть не допустила ни одной ошибки, то переходим ко второму шагу процедуры.
- Пытаемся обучить полученную сеть. Если сеть обучилась безошибочному решению задачи, то переходим к первому шагу процедуры, в противном случае переходим к шестому шагу.
- Восстанавливаем сеть в состояние до последнего выполнения третьего шага. Если в ходе выполнения шагов со второго по пятый был отконтрастирован хотя бы один параметр, (число обучаемых параметров изменилось), то переходим к первому шагу. Если ни один параметр не был отконтрастирован, то получена минимальная сеть.
Возможно использование различных обобщений этой процедуры. Например, контрастировать за один шаг процедуры не один параметр, а заданное пользователем число параметров. Наиболее радикальная процедура состоит в контрастировании половины параметров связей. Если контрастирование половины параметров не удается, то пытаемся контрастировать четверть и т.д. Другие варианты обобщения процедуры контрастирования будут описаны при описании решения задач. Результаты первых работ по контрастированию нейронных сетей с помощью описанной процедуры опубликованы в [47, 303, 304].
Контрастирование без ухудшения
Пусть нам дана только обученная нейронная сеть и обучающее множество. Допустим, что вид функции оценки и процедура обучения нейронной сети неизвестны. В этом случае так же возможно контрастирование сети. Предположим, что данная сеть идеально решает задачу. В этом случае возможно контрастирование сети даже при отсутствии обучающей выборки, поскольку ее можно сгенерировать используя сеть для получения ответов. Задача не ухудшающего контрастирования ставится следующим образом: необходимо так провести контрастирование параметров, чтобы выходные сигналы сети при решении всех примеров изменились не более чем на заданную величину. Для решения задача редуцируется на отдельный адаптивный сумматор: необходимо так изменить параметры, чтобы выходной сигнал адаптивного сумматора при решении каждого примера изменился не более чем на заданную величину.
Обозначим через 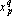 p-й входной сигнал сумматора при решении q-о примера; через p-й входной сигнал сумматора при решении q-о примера; через  – выходной сигнал сумматора при решении q-о примера; через – выходной сигнал сумматора при решении q-о примера; через 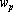 – вес p-о входного сигнала сумматора; через ε – требуемую точность; через n – число входных сигналов сумматора; через m – число примеров. Очевидно, что при решении примера выполняется равенство – вес p-о входного сигнала сумматора; через ε – требуемую точность; через n – число входных сигналов сумматора; через m – число примеров. Очевидно, что при решении примера выполняется равенство 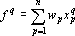 . Требуется найти такой набор индексов . Требуется найти такой набор индексов 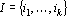 , что , что 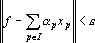 , где , где 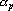 – новый вес p-о входного сигнала сумматора. Набор индексов будем строить по следующему алгоритму. – новый вес p-о входного сигнала сумматора. Набор индексов будем строить по следующему алгоритму.
- Положим
 , ,  , ,  , , 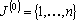 , k=0. , k=0.
- Для всех векторов
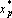 таких, что таких, что 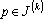 , проделаем следующее преобразование: если , проделаем следующее преобразование: если 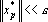 , то исключаем p из множества обрабатываемых векторов – , то исключаем p из множества обрабатываемых векторов – 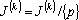 , в противном случае нормируем вектор на единичную длину – , в противном случае нормируем вектор на единичную длину – 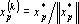 . .
- Если
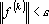 или или 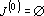 , то переходим к шагу 10. , то переходим к шагу 10.
- Находим
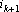 – номер вектора, наиболее близкого к – номер вектора, наиболее близкого к 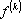 из условия из условия
- Исключаем из множества индексов обрабатываемых векторов:
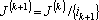 . .
- Добавляем в множество индексов найденных векторов:
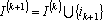
- Вычисляем не аппроксимированную часть (ошибку аппроксимации) вектора выходных сигналов:
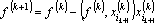
- Преобразуем обрабатываемые вектора к промежуточному представлению – ортогонализуем их к вектору
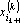 , для чего каждый вектор , для чего каждый вектор 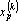 , у которого преобразуем по следующей формуле: , у которого преобразуем по следующей формуле: 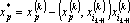 . .
- Увеличиваем k на единицу и переходим к шагу 2.
- Если k=0, то весь сумматор удаляется из сети и работа алгоритма завершается.
- Если k=n+1, то контрастирование невозможно и сумматор остается неизменным.
- В противном случае полагаем
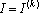 и вычисляем новые веса связей и вычисляем новые веса связей 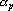 ( (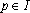 ) решая систему уравнений ) решая систему уравнений 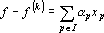 . .
- Удаляем из сети связи с номерами
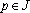 , веса оставшихся связей полагаем равными , веса оставшихся связей полагаем равными 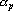 (). ().
Данная процедура позволяет производить контрастирование адаптивных сумматоров. Причем значения, вычисляемые каждым сумматором после контрастирования, отличаются от исходных не более чем на заданную величину. Однако, исходно была задана только максимально допустимая погрешность работы сети в целом. Способы получения допустимых погрешностей для отдельных сумматоров исходя из заданной допустимой погрешности для всей сети описаны в ряде работ [95 –97, 168, 210 – 214, 355].
Гибридная процедура контрастирования
Можно упростить процедуру контрастирования, описанную в разд. «Контрастирование без ухудшения». Предлагаемая процедура годится только для контрастирования весов связей адаптивного сумматора (см. разд. «Составные элементы»). Контрастирование весов связей производится отдельно для каждого сумматора. Адаптивный сумматор суммирует входные сигналы нейрона, умноженные на соответствующие веса связей. Для работы нейрона наименее значимым будем считать тот вес, который при решении примера даст наименьший вклад в сумму. Обозначим через входные сигналы рассматриваемого адаптивного сумматора при решении q-го примера. Показателем значимости веса назовем следующую величину: 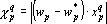 . Усредненный по всем примерам обучающего множества показатель значимости имеет вид . Усредненный по всем примерам обучающего множества показатель значимости имеет вид 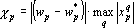 . Производим контрастирование по процедуре, приведенной в разд. «Контрастирование на основе показателей значимости». В самой процедуре контрастирования есть только одно отличие – вместо проверки на наличие ошибок при предъявлении всех примеров проверяется, что новые выходные сигналы сети отличаются от первоначальных не более чем на заданную величину. . Производим контрастирование по процедуре, приведенной в разд. «Контрастирование на основе показателей значимости». В самой процедуре контрастирования есть только одно отличие – вместо проверки на наличие ошибок при предъявлении всех примеров проверяется, что новые выходные сигналы сети отличаются от первоначальных не более чем на заданную величину.
Контрастирование при обучении
Существует еще один способ контрастирования нейронных сетей. Идея этого способа состоит в том, что функция оценки модернизируется таким способом, чтобы для снижения оценки было выгодно привести сеть к заданному виду. Рассмотрим решение задачи приведения параметров сети к выделенным значениям. Используя обозначения из предыдущих разделов требуемую добавку к функции оценки, являющуюся штрафом за отклонение значения параметра от ближайшего выделенного значения:, можно записать в виде 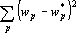 . .
Для решения других задач вид добавок к функции оценки много сложнее.
Определение показателей значимости
В данном разделе описан способ определения показателей значимости параметров и сигналов. . Далее будем говорить об определении значимости параметров. Показатели значимости сигналов сети определяются по тем же формулам с заменой параметров на сигналы.
Определение показателей значимости через градиент
Нейронная сеть двойственного функционирования может вычислять градиент функции оценки по входным сигналам и обучаемым параметрам сети
Показателем значимости параметра при решении q-о примера будем называть величину, которая показывает насколько изменится значение функции оценки решения сетью q-о примера если текущее значение параметра 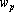 заменить на выделенное значение заменить на выделенное значение 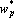 . Точно эту величину можно определить произведя замену и вычислив оценку сети. Однако учитывая большое число параметров сети вычисление показателей значимости для всех параметров будет занимать много времени. Для ускорения процедуры оценки параметров значимости вместо точных значений используют различные оценки [33, 65, 91]. Рассмотрим простейшую и наиболее используемую линейную оценку показателей значимости. Разложим функцию оценки в ряд Тейлора с точностью до членов первого порядка: . Точно эту величину можно определить произведя замену и вычислив оценку сети. Однако учитывая большое число параметров сети вычисление показателей значимости для всех параметров будет занимать много времени. Для ускорения процедуры оценки параметров значимости вместо точных значений используют различные оценки [33, 65, 91]. Рассмотрим простейшую и наиболее используемую линейную оценку показателей значимости. Разложим функцию оценки в ряд Тейлора с точностью до членов первого порядка: 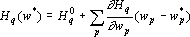 ,где ,где 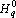 – значение функции оценки решения q-о примера при – значение функции оценки решения q-о примера при 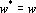 . Таким образом показатель значимости p-о параметра при решении q-о примера определяется по следующей формуле: . Таким образом показатель значимости p-о параметра при решении q-о примера определяется по следующей формуле:
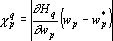 |
(1) |
Показатель значимости (1) может вычисляться для различных объектов. Наиболее часто его вычисляют для обучаемых параметров сети. Однако показатель значимости вида (1) применим и для сигналов. Как уже отмечалось в главе «Описание нейронных сетей» сеть при обратном функционировании всегда вычисляет два вектора градиента – градиент функции оценки по обучаемым параметрам сети и по всем сигналам сети. Если показатель значимости вычисляется для выявления наименее значимого нейрона, то следует вычислять показатель значимости выходного сигнала нейрона. Аналогично, в задаче определения наименее значимого входного сигнала нужно вычислять значимость этого сигнала, а не сумму значимостей весов связей, на которые этот сигнал подается.
Усреднение по обучающему множеству
Показатель значимости параметра 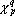 зависит от точки в пространстве параметров, в которой он вычислен и от примера из обучающего множества. Существует два принципиально разных подхода для получения показателя значимости параметра, не зависящего от примера. При первом подходе считается, что в обучающей выборке заключена полная информация о всех возможных примерах. В этом случае, под показателем значимости понимают величину, которая показывает насколько изменится значение функции оценки по обучающему множеству, если текущее значение параметра заменить на выделенное значение . Эта величина вычисляется по следующей формуле: зависит от точки в пространстве параметров, в которой он вычислен и от примера из обучающего множества. Существует два принципиально разных подхода для получения показателя значимости параметра, не зависящего от примера. При первом подходе считается, что в обучающей выборке заключена полная информация о всех возможных примерах. В этом случае, под показателем значимости понимают величину, которая показывает насколько изменится значение функции оценки по обучающему множеству, если текущее значение параметра заменить на выделенное значение . Эта величина вычисляется по следующей формуле:
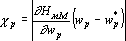 . . |
(2) |
В рамках другого подхода обучающее множество рассматривают как случайную выборку в пространстве входных параметров. В этом случае показателем значимости по всему обучающему множеству будет служить результат некоторого усреднения по обучающей выборке.
Существует множество способов усреднения. Рассмотрим два из них. Если в результате усреднения показатель значимости должен давать среднюю значимость, то такой показатель вычисляется по следующей формуле:
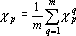 . . |
(3) |
Если в результате усреднения показатель значимости должен давать величину, которую не превосходят показатели значимости по отдельным примерам (значимость этого параметра по отдельному примеру не больше чем ), то такой показатель вычисляется по следующей формуле:
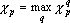 . . |
(4) |
Показатель значимости (4) хорошо зарекомендовал себя при использовании в работах группы НейроКомп.
Накопление показателей значимости
Все показатели значимости зависят от точки в пространстве параметров сети, в которой они вычислены, и могут сильно изменяться при переходе от одной точки к другой. Для показателей значимости, вычисленных с использованием градиента эта зависимость еще сильнее, поскольку при обучении по методу наискорейшего спуска (см. раздел «Метод наискорейшего спуска») в двух соседних точках пространства параметров, в которых вычислялся градиент, градиенты ортогональны. Для снятия зависимости от точки пространства используются показатели значимости, вычисленные в нескольких точках. Далее они усредняются по формулам аналогичным (3) и (4). Вопрос о выборе точек в пространстве параметров в которых вычислять показатели значимости обычно решается просто. В ходе нескольких шагов обучения по любому из градиентных методов при каждом вычислении градиента вычисляются и показатели значимости. Число шагов обучения, в ходе которых накапливаются показатели значимости, должно быть не слишком большим, поскольку при большом числе шагов обучения первые вычисленные показатели значимости теряют смысл, особенно при использовании усреднения по формуле (4).
Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
|