Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
Лекции 2 и 3. Сети естественной классификации
В данном разделе курса будут рассмотрены сети естественной классификации. Этот класс сетей имеет еще одно название – сети, обучающиеся без учителя. Второе название имеет более широкое распространение, однако, является в корне неверным. В дальнейшем в нашем курсе будет рассмотрена модель универсального нейрокомпьютера в которой будет явно выделен компонент учитель и описаны его функции. В этом смысле данный вид сетей обучается с явно заданным учителем. Когда давалось это название, имелось в виду, что сети данного вида не обучают воспроизведению заранее заданной классификации. Именно поэтому название «Сети естественной классификации» является наиболее точным для данного класса сетей. Наиболее известной сетью данного вида является сеть Кохонена [131, 132].
Содержательная постановка задачи
Достаточно часто на практике приходится сталкиваться со следующей задачей: есть таблица данных (результаты измерений, социологических опросов или обследований больных). Необходимо определить каким закономерностям подчиняются данные в таблице. Следует заметить, что характерный размер таблицы – порядка ста признаков и порядка нескольких сотен или тысяч объектов. Ручной анализ таких объемов информации фактически невозможен.
Первым шагом в решении данной задачи является группировка (кластеризация, классификация) объектов в группы (кластеры, классы) «близких» объектов. Далее исследуются вопросы того, что общего между объектами одной группы, и что отличает их от других групп. Далее будем использовать термин классификация и говорить о классах близких объектов.
Слово близких, в постановке задачи, взято в кавычки, поскольку под близостью можно понимать множество разных отношений близости. Далее будет рассмотрен ряд примеров различных видов близости.
К сожалению, вид близости и число классов приходится определять исследователю, хотя существует набор методов (методы отжига) позволяющих оптимизировать число классов.
Формальная постановка задачи
Рассмотрим множество из m объектов 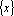 , каждый из которых является n-мерным вектором с действительными координатами (в случае комплексных координат особых трудностей с данным методом также не возникает, но формулы становятся более сложными, а комплексные значения признаков случаются редко). , каждый из которых является n-мерным вектором с действительными координатами (в случае комплексных координат особых трудностей с данным методом также не возникает, но формулы становятся более сложными, а комплексные значения признаков случаются редко).
Зададим пространство ядер классов E, и меру близости 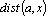 , где a – точка из пространства ядер, а x – точка из пространства объектов. Тогда для заданного числа классов k необходимо подобрать k ядер таким образом, чтобы суммарная мера близости была минимальной. Суммарная мера близости записывается в следующем виде: , где a – точка из пространства ядер, а x – точка из пространства объектов. Тогда для заданного числа классов k необходимо подобрать k ядер таким образом, чтобы суммарная мера близости была минимальной. Суммарная мера близости записывается в следующем виде:
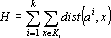 , , |
(1) |
где 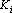 – множество объектов i-о класса. – множество объектов i-о класса.
Сеть Кохонена
Сеть Кохонена для классификации на k классов состоит из k нейронов (ядер), каждый из которых вычисляет близость объекта к своему классу. Все нейроны работают параллельно. Объект считается принадлежащим к тому классу, нейрон которого выдал минимальный сигнал. При обучении сети Кохонена считается, что целевой функционал не задан (отсюда и название «Обучение без учителя»). Однако алгоритм обучения устроен так, что в ходе обучения минимизируется функционал (1), хотя и немонотонно.
Обучение сети Кохонена
Предложенный финским ученым Кохоненом метод обучения сети решению такой задачи состоит в следующем. Зададим некоторый начальный набор параметров нейронов. Далее предъявляем сети один объект x. Находим нейрон, выдавший максимальный сигнал. Пусть номер этого нейрона i. Тогда параметры нейрона модифицируются по следующей формуле:
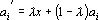 |
(2) |
Затем сети предъявляется следующий объект, и так далее до тех пор, пока после очередного цикла предъявления всех объектов не окажется, что параметры всех нейронов изменились на величину меньшую наперед заданной точности ε. В формуле (2) параметр λ называют скоростью обучения. Для некоторых мер близости после преобразования (2) может потребоваться дополнительная нормировка параметров нейрона.
Сеть Кохонена на сфере
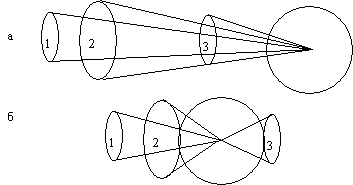
Рис 1. Три четко выделенных кластера в исходном пространстве сливаются
полностью (а) или частично (б) при проецировании на единичную сферу.
|
Одним из наиболее распространенных и наименее удачных (в смысле практических применений) является сферическая сеть Кохонена. В этой постановке предполагается, что все вектора-объекты имеют единичную длину. Ядра (векторы параметров нейронов) также являются векторами единичной длины. Привлекательность этой модели в том, что нейрон вычисляет очень простую функцию – скалярное произведение вектора входных сигналов на вектор параметров. Недостатком является большая потеря информации во многих задачах. На рис. 1 приведен пример множества точек разбитого на три четко выделенных кластера в исходном пространстве, которые сливаются полностью или частично при проецировании на единичную сферу.
Эта модель позволяет построить простые иллюстрации свойств обучения сетей Кохонена, общие для всех методов. Наиболее иллюстративным является пример, когда в двумерном пространстве множество объектов равномерно распределено по сфере (окружности), причем объекты пронумерованы против часовой стрелке. В начальный момент времени ядра являются противоположно направленными векторами.
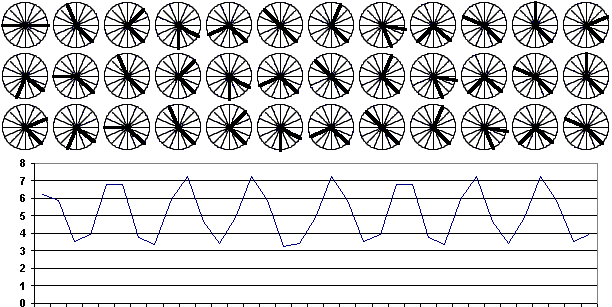
Рис. 2. Положение ядер при последовательном предъявлении объектов со скоростью обучения 0,5. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер. |
На рис. 2 приведены состояния сети Кохонена перед началом обучения и после каждой эпохи обучения. Эпохой принято называть полный цикл предъявления обучающего множества (всех объектов, по которым проводится обучение). Ядра на рисунках обозначены жирными линиями. Из рисунка видно, что обучение зациклилось – после каждой эпохи сумма квадратов изменений координат всех ядер то уменьшается, то возрастает. В литературе приводится целый ряд способов избежать зацикливания. Один из них – обучать с малым шагом. На рис. 3 приведены состояния сети при скорости обучения 0,01.
Рис. 3. Положение ядер при последовательном предъявлении объектов со скоростью обучения 0,01. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер. |
Из анализа рис.3 видно, что изменения ядер уменьшаются со временем. Однако в случае изначально неудачного распределения ядер потребуется множество шагов для перемещения их к «своим» кластерам (см. рис. 4).

Рис. 4. Обучение сети Кохонена со скоростью 0,01 (107 эпох) |
Следующая модификация алгоритма обучения состоит в постепенном уменьшении скорости обучения. Это позволяет быстро приблизиться к «своим» кластерам на высокой скорости и произвести доводку при низкой скорости. Для этого метода необходимым является требование, чтобы последовательность скоростей обучения образовывала расходящийся ряд, иначе остановка алгоритма будет достигнута не за счет выбора оптимальных ядер, а за счет ограниченности точности вычислений. На рис. 5 приведены состояния сети Кохонена при использовании начальной скорости обучения 0,5 и уменьшения скорости в соответствии с натуральным рядом (1, 1/2, 1/3,…). Уменьшение скорости обучения производилось после каждой эпохи. Из графика изменения суммы квадратов изменений координат ядер видно, что этот метод является лучшим среди рассмотренных. На рис. 6 приведены результаты применения этого метода в случае неудачного начального положения ядер. Распределение объектов выбрано то же, что и на рисунке 4 – два класса по 8 объектов, равномерно распределенных в интервалах [π/4,3 π/4] и [5π/4,7π/4].
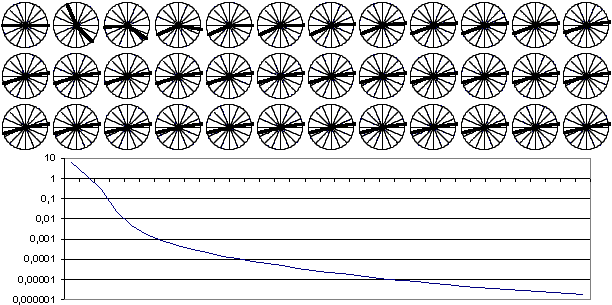
Рис. 5. Положение ядер при последовательном предъявлении объектов со снижением скорости обучения с 0,5 в соответствии с последовательностью 1/n. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер (в логарифмической шкале). |
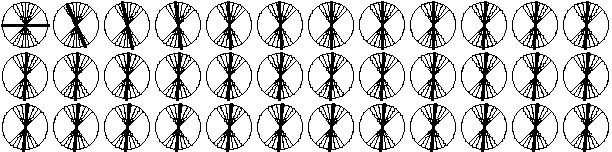
Рис. 6. Обучение сети Кохонена со снижением скорости с 0,5. |
Альтернативой методу с изменением шага считается метод случайного перебора объектов в пределах эпохи. Основная идея этой модернизации метода состоит в том, чтобы избежать направленного воздействия.
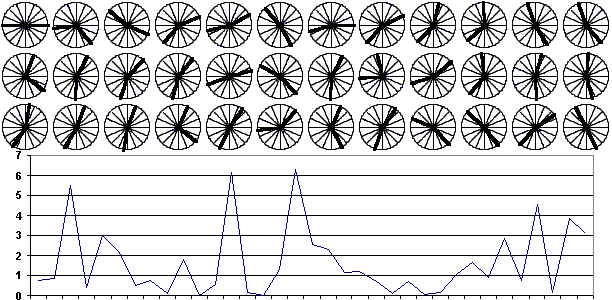
Рис. 7. Положение ядер при предъявлении объектов в случайном порядке со скоростью обучения 0,5. Состояние до обучения и после каждой эпохи обучения. Ниже приведен график изменения суммы квадратов изменений координат ядер. |
Под направленным воздействием подразумевается порядок предъявления объектов, который влечет смещение ядра от оптимального положения в определенную сторону. Именно эффект направленного воздействия приводит к тому, что стандартный метод зацикливается (отметим, что пример с равномерно распределенными по окружности объектами, пронумерованными против часовой стрелки, специально строился для оказания направленного воздействия). Именно из-за направленного воздействия ядра на рис. 6 направлены не строго вертикально. Случайный порядок перебора объектов позволяет избежать, точнее снизить эффект, направленного воздействия. Однако из рис.7, на котором приведены результаты применения метода перебора объектов в случайном порядке к задаче с равномерно распределенными по окружности объектами, видно, что полностью снять эффект направленного воздействия этот метод не позволяет.
Возможны различные сочетания рассмотренных выше методов. Например, случайный перебор объектов в сочетании с уменьшением скорости обучения. Именно такая комбинация методов является наиболее мощным методом среди методов пообъектного обучения сетей Кохонена.
Метод динамических ядер
Альтернативой методам пообъектного обучения сетей Кохонена является метод динамических ядер, который напрямую минимизирует суммарную меру близости (1). Метод является итерационной процедурой, каждая итерация которой состоит из двух шагов. Сначала задаются начальные значения ядер. Затем выполняют следующие шаги:
- Разбиение на классы при фиксированных значениях ядер:
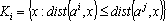 |
(3) |
- Оптимизация значений ядер при фиксированном разбиении на классы:
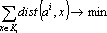 |
(4) |
В случае равенства в формуле (3) объект относят к классу с меньшим номером. Процедура останавливается если после очередного выполнения разбиения на классы (3) не изменился состав ни одного класса.
Исследуем сходимость метода динамических ядер. На шаге (3) суммарная мера близости (1) может измениться только при переходе объектов из одного класса в другой. Если объект перешел из j-о класса в i-й, то верно неравенство  . То есть при переходе объекта из одного класса в другой суммарная мера близости не возрастает. На шаге (4) минимизируются отдельные слагаемые суммарной меры близости (1). Поскольку эти слагаемые независимы друг от друга, то суммарная мера близости на шаге (4) не может возрасти. При это если на шаге (4) суммарная мера близости не уменьшилась, то ядра остались неизменными и при выполнении следующего шага (3) будет зафиксировано выполнение условия остановки. И наконец, учитывая, что конечное множество объектов можно разбить на конечное число классов только конечным числом способов, получаем окончательное утверждение о сходимости метода динамических ядер. . То есть при переходе объекта из одного класса в другой суммарная мера близости не возрастает. На шаге (4) минимизируются отдельные слагаемые суммарной меры близости (1). Поскольку эти слагаемые независимы друг от друга, то суммарная мера близости на шаге (4) не может возрасти. При это если на шаге (4) суммарная мера близости не уменьшилась, то ядра остались неизменными и при выполнении следующего шага (3) будет зафиксировано выполнение условия остановки. И наконец, учитывая, что конечное множество объектов можно разбить на конечное число классов только конечным числом способов, получаем окончательное утверждение о сходимости метода динамических ядер.
Процедура (3), (4) сходится за конечное число шагов, причем ни на одном шаге не происходит возрастания суммарной меры близости.
На первом из рассмотренных выше примеров, с равномерно распределенными по окружности объектами, при любом начальном положении ядер (за исключением совпадающих ядер) метод динамических ядер остановится на втором шаге, поскольку при второй классификации (3) состав классов останется неизменным.
На втором из примеров, рассмотренных выше (см. рис. 4, 6) примеров при том же начальном положении ядер, метод динамических ядер остановится после первого шага, не изменив положения ядер. Однако такое положение ядер не соответствует обычному представлению о «хорошей» классификации. Причина – неудачное начальное положение ядер (созданное специально).
Выбор начального приближения
Как и во многих других итерационных методах, в задаче обучения сети Кохонена и в методе динамических ядер важным является вопрос о хорошем выборе начального приближения (первоначальных значений ядер). Существует множество методов выбора начального приближения.
Наиболее простым способом решения этой задачи в случае, когда ядра являются точками того же пространства, что и объекты, является выбор в качестве начального приближения значений ядер значений объектов. Например первое ядро кладем равным первому объекту, второе – второму и т.д. К сожалению этот метод не работает когда пространство ядер и пространство объектов не совпадают. Далее будут приведены примеры классификаций, в которых пространства ядер и объектов различны.
Самым универсальным способом задания начального положения ядер является задание начального разбиения объектов на классы. При этом в начальном разбиении могут участвовать не все объекты. Далее решая задачу (4) получаем начальные значения ядер. Далее можно использовать метод динамических ядер.
Примеры видов классификации
В данном разделе описаны некоторые виды классификации и соответствующие им меры близости. Приведены формулы решения задачи (4) при использовании метода динамических ядер. Для других видов классификации решение задачи (4) строится аналогично.
Сферическая модель
Один вид классификации – сеть Кохонена на сфере был описан ранее. Получим формулы для решения задачи (4) при мере близости «минус скалярное произведение» (минус перед скалярным произведением нужен для того, чтобы решать задачу минимизации (1) и (4), поскольку, чем ближе векторы, тем больше скалярное произведение).
Обозначим через 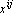 объекты, принадлежащие i-у классу. Учитывая дополнительное условие на значение ядра – его единичную длину – и применяя метод множителей Лагранжа для решения задач поиска условного экстремума, получим следующую задачу: объекты, принадлежащие i-у классу. Учитывая дополнительное условие на значение ядра – его единичную длину – и применяя метод множителей Лагранжа для решения задач поиска условного экстремума, получим следующую задачу:
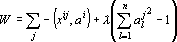 |
(5) |
Дифференцируя (5) по каждой из координат ядра и по множителю Лагранжа λ, и приравнивая результат дифференцирования к нулю, получим следующую систему уравнений:
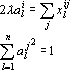 |
(6) |
Выразив из первых уравнений 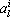 и подставив результат в последнее выражение найдем λ, а затем найдем координаты ядра: и подставив результат в последнее выражение найдем λ, а затем найдем координаты ядра:
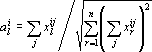 |
(7) |
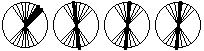
Рис. 8. Решение задачи методом динамических ядер |
Подводя итог, можно сказать, что новое положение ядра есть среднее арифметическое объектов данного класса, нормированное на единичную длину.
На рис. 8. Приведено решение второго примера методом обучения сети Кохонена с уменьшением скорости с 0,5, а на рис. 9 - решение той же задачи методом динамических ядер. В качестве первоначального значения ядер выбраны два первых объекта.
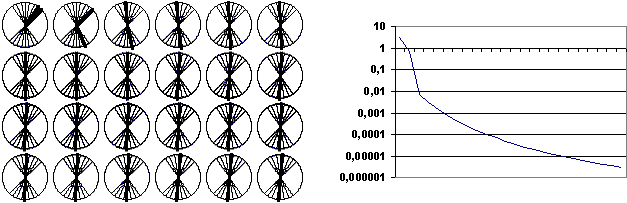
Рис. 9. Решение задачи с помощью обучения сети Кохонена со снижением скорости обучения с 0,5. График суммарного изменения разностей координат ядер. |
Пространственная модель
Эта модель описывает наиболее естественную классификацию. Нейрон пространственной сети Кохонена приведен в главе «Описание нейронных сетей». Ядра являются точками в пространстве объектов. Мера близости – квадрат обычного евклидова расстояния. Обучение сети Кохонена ведется непосредственно по формуле (2). Задача (4) имеет вид:
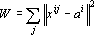 |
(8) |
Дифференцируя (8) по каждой координате ядра и приравнивая результат к нулю получаем следующую систему уравнений:
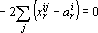 . .
Преобразуя полученное выражение получаем
 , , |
(9) |
где 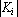 – мощность i-о класса (число объектов в классе). Таким образом, оптимальное ядро класса – среднее арифметическое всех объектов класса. – мощность i-о класса (число объектов в классе). Таким образом, оптимальное ядро класса – среднее арифметическое всех объектов класса.
Модель линейных зависимостей
Это первая модель, которая может быть решена методом динамических ядер, но не может быть получена с помощью обучения сети Кохонена, поскольку ядра не являются точками в пространстве объектов. Ядрами в данной модели являются прямые, а мерой близости – квадрат расстояния от точки (объекта) до прямой. Прямая в n-мерном пространстве задается парой векторов: 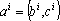 . Первый из векторов задает смещение прямой от начала координат, а второй является направляющим вектором прямой. Точки прямой задаются формулой . Первый из векторов задает смещение прямой от начала координат, а второй является направляющим вектором прямой. Точки прямой задаются формулой 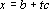 , где t – параметр, пробегающий значения от минус бесконечности до плюс бесконечности. t имеет смысл длины проекции вектора x-b на вектор c. Сама проекция равна tc. При положительном значении вектор проекции сонаправлен с вектором c, при отрицательном – противоположно направлен. При условии, что длина вектора c равна единице, проекция вычисляется как скалярное произведение , где t – параметр, пробегающий значения от минус бесконечности до плюс бесконечности. t имеет смысл длины проекции вектора x-b на вектор c. Сама проекция равна tc. При положительном значении вектор проекции сонаправлен с вектором c, при отрицательном – противоположно направлен. При условии, что длина вектора c равна единице, проекция вычисляется как скалярное произведение 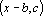 . В противном случае скалярное произведение необходимо разделить на квадрат длины c. Мера близости вектора (точки) x определяется как квадрат длины разности вектора x и его проекции на прямую. При решении задачи (4) необходимо найти минимум следующей функции: . В противном случае скалярное произведение необходимо разделить на квадрат длины c. Мера близости вектора (точки) x определяется как квадрат длины разности вектора x и его проекции на прямую. При решении задачи (4) необходимо найти минимум следующей функции:
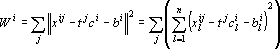
Продифференцируем целевую функцию по неизвестным  и приравняем результаты к нулю. и приравняем результаты к нулю.
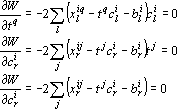 |
(10) |
Выразим из последнего уравнения в (10) 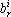 : :
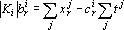 |
(11) |
В качестве 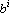 можно выбрать любую точку прямой. Отметим, что для любого набора векторов и любой прямой с ненулевым направляющим вектором можно выбрать любую точку прямой. Отметим, что для любого набора векторов и любой прямой с ненулевым направляющим вектором 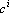 на прямой найдется такая точка , что сумма проекций всех точек на прямую будет равна нулю. Выберем в качестве такую точку. Второе слагаемое в правой части (11) является r-й координатой суммы проекций всех точек на искомую прямую и, в силу выбора точки равно нулю. Тогда получаем формулу для определения : на прямой найдется такая точка , что сумма проекций всех точек на прямую будет равна нулю. Выберем в качестве такую точку. Второе слагаемое в правой части (11) является r-й координатой суммы проекций всех точек на искомую прямую и, в силу выбора точки равно нулю. Тогда получаем формулу для определения :
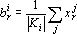 |
(12) |
Из первых двух уравнений (10) получаем формулы для определения остальных неизвестных:
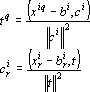 |
(13) |
Поиск решения задачи (4) для данного вида классификации осуществляется по следующему алгоритму:
- Вычисляем по формуле (12).
- Вычисляем t по первой формуле в (13).
- Вычисляем по второй формуле в (13).
- Если изменение значения превышает заданную точность, то переходим к шагу 2, в противном случае вычисления закончены.
Определение числа классов
До этого момента вопрос об определении числа классов не рассматривался. Предполагалось, что число классов задано исходя из каких-либо дополнительных соображений. Однако достаточно часто дополнительных соображений нет. В этом случае число классов определяется экспериментально. Но простой перебор различных чисел классов часто неэффективен. В данном разделе будет рассмотрен ряд методов, позволяющих определить «реальное» число классов.
Для иллюстрации будем пользоваться пространственной моделью в двумерном пространстве. На рис, 10 приведено множество точек, которые будут разбиваться на классы.
Простой подбор
Идея метода состоит в том, что бы начав с малого числа классов постепенно увеличивать его до тех пор, пока не будет получена «хорошая» классификация. Понятие «хорошая» классификация может быть формализовано по разному. При простом подборе классов как правило оперируют таким понятием, как часто воспроизводящийся класс. Проводится достаточно большая серия классификаций с различным начальным выбором классов. Определяются классы, которые возникают в различных классификациях. Считаются частоты появления таких классов. Критерием получения «истинного» числа классов может служить снижение числа часто повторяющихся классов. То есть при числе классов k число часто повторяющихся классов заметно меньше чем при числе классов k-1 и k+1. Начинать следует с двух классов.
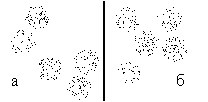
Рис. 10. Множества точек для классификации |
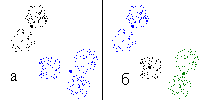
Рис. 11. Разбиение множества на два (а) и три (б) класса |
Рассмотрим два примера. На рис. 10 приведены множества точек, которые будут разбиваться на классы. При каждом числе классов проводится 100 разбиений на классы. В качестве начальных значений ядер выбираются случайные точки.
Сначала рассмотрим множество точек, приведенное на рис. 10а. При классификациях на два класса во всех 100 случаях получаем классификацию, приведенную на рис. 11. Таким образом, получено устойчивое (абсолютно устойчивое) разбиение множества точек на два класса.
В принципе можно на этом остановиться. Однако возможно, что мы имеем дело с иерархической классификацией, то есть каждый (или один) из полученных на данном этапе классов может в дальнейшем разбиться на несколько классов. Для проверки этой гипотезы проведем классификацию на три класса. Во всех 100 случаях получаем одно и то же разбиение, приведенное на рис. 11б. Гипотеза об иерархической классификации получила подтверждение. Предпринимаем попытку дальнейшей детализации - строим разбиение на четыре класса. При этом возникают три различных разбиения, приведенных на рис. 12. При этом разбиение, приведенное на рис. 12в возникает всего два раза из 100. Разбиение, приведенное на рис. 12а - 51 раз, на рис. 12б - 47 раз. Если отбросить редкие классы, то получим набор из семи классов. Один из них воспроизводится 98 раз (красное множество на рис. 12а). Остальные шесть классов образуют две тройки. Каждая тройка состоит из двух <маленьких> классов и <большого> класса, являющегося их объединением. Из этого анализа напрашивается вывод о том, что <реальное> число классов равно пяти. Проверяем это предположение.
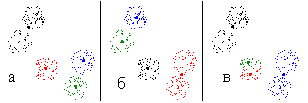
Рис. 12. Три варианта классификации на четыре класса |
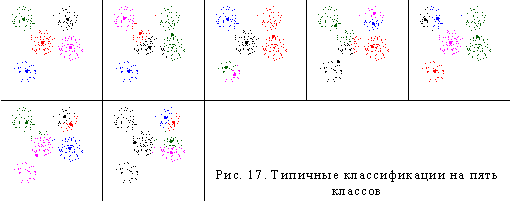
Результаты классификации на пять классов приведены на рис. 13. Выделенные на предыдущем этапе пять «маленьких» классов были воспроизведены 84, 67, 64, 68 и 69 раз. Два «больших» класса, выделенных на предыдущем этапе, были воспроизведены 24 и 30 раз. Остальные классы были получены не более чем 4 раза, а большинство по одному разу. Проверим классификацию на 6 классов. Малые классы были получены 75, 70, 53, 43, 44 раза. Один из больших классов – 16 раз. Из остальных классов один был воспроизведен 24 раза, второй – 19 раз. Все другие классы появлялись не более 10 раз. Всего получено 149 классов.

Рис. 13. Различные варианты классификации на пять классов |
Таким образом, получена трехуровневая иерархическая классификация: Два класса первого уровня приведены на рис. 11а. Три класса второго уровня – на рис. 11б. Пять классов третьего уровня – на рис. 13а.
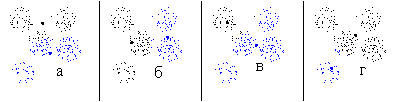
Рис. 14. Классификации на два класса |
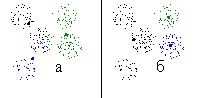
Рис. 15. Типы классификаций на три класса |
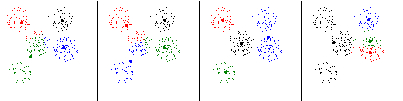
Рис. 16. Типичные классификации на четыре класса |
Проведем туже процедуру для множества точек, приведенного на рис. 10б. При классификации на два класса получим четыре типичных варианта классификаций, приведенных на рис. 14. Всего получено 14 классов. Два класса были получены по 69 раз, два по 18 раз. Остальные не более 6 раз.
Проведем классификацию на три класса. Получим всего два типа классификаций, приведенных на рис. 15. Всего получено 12 классов. Одна тройка классов была воспроизведена 14 раз, вторая – 26 раз, третья – 27 и четвертая – 33 раза. После классификации на четыре класса получены четыре типичных классификации, приведенные на рис. 16. Всего получено 54 класса. Пять из них получены 36, 37, 36, 36 и 57 раз. Еще 4 класса получены 14 раз, два класса – 10 раз, остальные не более 6 раз. При классификации на пять классов получено семь типичных классификаций, приведенных на рис. 17. Всего было получено 49 классов. При этом пять классов были получены 91, 82, 87, 92 и 82 раза. Еще один класс – 8 раз. Остальные классы не более 3 раз. Увеличился разрыв между «редкими» и «частыми» классами. Сократилось число часто повторяющихся классов. Для контроля проведем классификацию на 6 классов. Всего получено 117 классов. Из них пять были получены 86, 81, 57, 76 и 69 раз. Все остальные классы были получены не более 9 раз.
 |
Таким образом, на основе классификаций на четыре, пять и шесть классов можно утверждать, что «реально» существует пять классов.
Методы отжига
Предложенный метод перебора количества классов хорошо работает при небольшом «реальном» числе классов. При достаточно большом числе классов и большом объеме множества точек, которые необходимо разбить на классы, такая процедура подбора становится слишком медленной. Действительно, число пробных классификаций должно быть сравнимо по порядку величины с числом точек. В результате получается большие вычислительные затраты, которые чаще всего тратятся впустую (важны несколько значений числа классов вблизи «реального» числа классов).
Альтернативой методу перебора служит метод отжига. Идея метода отжига состоит в том, что на основе критерия качества класса принимается решение об удалении этого класса, разбиении класса на два или о слиянии этого класса с другим. Если класс «хороший», то он остается без изменений. Существует много различных критериев качества класса. Рассмотрим некоторые из них.
- Количественный критерий. Класс, в котором менее N точек считается пустым и полежит удалению. Порог числа точек выбирается из смысла задачи и вида меры близости.
- Критерий равномерности. Средняя мера близости точек класса от ядра должна быть не менее половины или трети от максимума меры близости точек от ядра (радиуса класса). Если это не так, то класс разбивается на два (порождается еще одно ядро вблизи первоначального).
- Критерий сферической разделимости. Два класса считаются сферически разделимыми, если сумма радиусов двух классов меньше расстояния между ядрами этих классов. Если классы сферически неразделимы, то эти классы сливаются в один.
Очевидно, что третий критерий применим только в тех случаях, когда ядра классов являются точками того же пространства, что и те точки, которые составляют классы. Все приведенные критерии неоднозначны и могут меняться в зависимости от требований задачи. Так вместо сферической разделимости можно требовать эллиптической разделимости и т.д.
Начальное число классов можно задавать по разному. Например, начать с двух классов и позволить сети «самой» увеличивать число классов. Или начать с большого числа классов и позволить сети отбросить «лишние» классы. В первом случае система может остановиться в случае наличия иерархической классификации (пример 1 из предыдущего раздела). Начиная с большого числа классов, мы рискуем не узнать о существовании иерархии классов.
Другим критерием может служить плотность точек в классе. Определим объем класса как объем шара с центром в ядре класса и радиусом равным радиусу класса. Для простоты можно считать объем класса равным объему куба с длинной стороны равной радиусу класса (объем шара будет отличаться от объема куба на постоянный множитель, зависящий только от размерности пространства). Плотностью класса будем считать отношение числа точек в классе к объему класса. Отметим, что этот критерий применим для любых мер близости, а не только для тех случаев, когда ядра и точки принадлежат одному пространству.
Метод применения этого критерия прост. Разбиваем первый класс на два и запускаем процедуру настройки сети (метод динамических ядер или обучение сети Кохонена). Если плотности обоих классов, полученных разбиением одного класса, не меньше плотности исходного класса, то считаем разбиение правильным. В противном случае восстанавливаем классы, предшествовавшие разбиению, и переходим к следующему классу. Если после очередного просмотра всех классов не удалось получить ни одного правильного разбиения, то считаем полученное число классов соответствующим «реальному». Эту процедуру следует запускать с малого числа классов, например, с двух.
Проведем процедуру определения числа классов для множества точек, приведенного на рис. 10а. Результаты приведены на рис. 18. Порядок классов 1-й класс – черный цвет, 2-й класс – синий, 3-й – зеленый, 4-й – красный, 5-й – фиолетовый, 6-й – желтый.
Рассмотрим последовательность действий, отображенную на рис. 18.
Первый рисунок – результат классификации на два класса.
Второй рисунок – первый класс разбит на два. Результат классификации на три класса. Плотности увеличились. Разбиение признано хорошим.
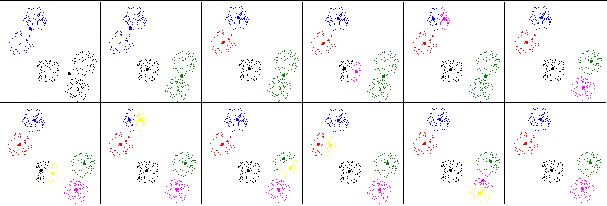
Рис. 18. Результат применения критерия плотности классов для определения числа классов к множеству точек, приведенному на рис. 10а. |
Третий рисунок – первый класс разбит на два. Результат классификации на четыре класса. Плотности увеличились. Разбиение признано хорошим.
Четвертый рисунок – первый класс разбит на два. Результат классификации на пять классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к третьему рисунку.
Пятый рисунок – второй класс разбит на два. Результат классификации на пять классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к третьему рисунку.
Шестой рисунок – третий класс разбит на два. Результат классификации на пять классов. Плотности увеличились. Разбиение признано хорошим.
Седьмой рисунок – первый класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Восьмой рисунок – второй класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Девятый рисунок – третий класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Десятый рисунок – четвертый класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Одинадцатый рисунок – пятый класс разбит на два. Результат классификации на шесть классов. Плотности не увеличились. Разбиение отвергнуто. Возврат к шестому рисунку.
Двенадцатый рисунок (совпадает с шестым) – окончательный результат.
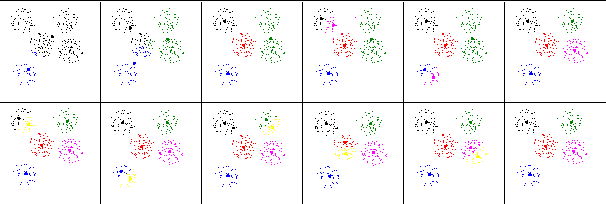
Рис. 19. Результат применения критерия плотности классов для определения числа классов к множеству точек, приведенному на рис. 10б. |
На рис. 19 приведен результат применения плотностного критерия определения числа классов для множества точек, приведенного на рис. 10б.
Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
|