Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
Лекции 11.2, 12. Учитель
Этот компонент не является столь универсальным как задачник, оценка или нейронная сеть, поскольку существует ряд алгоритмов обучения жестко привязанных к архитектуре нейронной сети. Примерами таких алгоритмов могут служить обучение (формирование синаптической карты) сети Хопфилда [312], обучение сети Кохонена [131, 132] и ряд других аналогичных сетей. Однако в главе «Описание нейронных сетей» приводится способ формирования сетей, позволяющий обучать сети Хопфилда [312] и Кохонена [131, 132] методом обратного распространения ошибки. Описываемый в этой главе компонент учитель ориентирован в первую очередь на обучение двойственных сетей (сетей обратного распространения ошибки).
Что можно обучать методом двойственности
Как правило, метод двойственности (обратного распространения ошибки) используют для подстройки параметров нейронной сети. Однако, как было показано в главе «Описание нейронных сетей», сеть может вычислять не только градиент функции оценки по обучаемым параметрам сети, но и по входным сигналам сети. Используя градиент функции оценки по входным сигналам сети можно решать задачу, обратную по отношению к обучению нейронной сети.
Рассмотрим следующий пример. Пусть есть сеть, обученная предсказывать по текущему состоянию больного и набору применяемых лекарств состояние больного через некоторый промежуток времени. Поступил новый больной. Его параметры ввели сети и она выдала прогноз. Из прогноза следует ухудшение некоторых параметров состояния больного. Возьмем выданный сетью прогноз, заменим значения параметров, по которым наблюдается ухудшение, на желаемые значения. Полученный вектор ответов объявим правильным ответом. Имея правильный ответ и ответ, выданный сетью, вычислим градиент функции оценки по входным сигналам сети. В соответствии со значениями элементов градиента изменим значения входных сигналов сети так, чтобы оценка уменьшилась. Проделав эту процедуру несколько раз, получим вектор входных сигналов, порождающих правильный ответ. Далее врач должен определить, каким способом (какими лекарствами или процедурами) перевести больного в требуемое (полученное в ходе обучения входных сигналов) состояние. В большинстве случаев часть входных сигналов не подлежит изменению (например пол или возраст больного). В этом случае эти входные сигналы должны быть помечены как не обучаемые (см. использование маски обучаемости входных сигналов в главе «Описание нейронных сетей»).
Таким образом, способность сетей вычислять градиент функции оценки по входным параметрам сети позволяет решать вполне осмысленную обратную задачу: так подобрать входные сигналы сети, чтобы выходные сигналы удовлетворяли заданным требованиям.
Кроме того, использование нейронных сетей позволяет ставить новые вопросы перед исследователем. В практике группы «НейроКомп» был следующий случай. Была поставлена задача обучить сеть ставить диагноз вторичного иммунодефицита по данным анализов крови и клеточного метаболизма. Вся обучающая выборка была разбита на два класса: больные и здоровые. При анализе базы данных стандартными статистическими методами значимых отличий обнаружить не удалось. Сеть оказалась не способна обучиться. Далее у исследователя было два пути: либо увеличить число нейронов в сети, либо определить, что мешает обучению. Исследователи выбрали второй путь. При обучении сети была применена следующая процедура: как только обучение сети останавливалось из-за невозможности дальнейшего уменьшения оценки, пример, имеющий наихудшую оценку, исключался из обучающего множества. После того, как сеть обучилась решению задачи на усеченном обучающем множестве, был проведен анализ исключенных примеров. Выяснилось, что исключено около половины больных. Тогда множество больных было разбито на два класса – больные1 (оставшиеся в обучающем множестве) и больные2 (исключенные). При таком разбиении обучающей выборки стандартные методы статистики показали значимые различия в параметрах классов. Обучение сети классификации на три класса быстро завершилось полным успехом. При содержательном анализе примеров, составляющих классы больные1 и больные2, было установлено, что к классу болные1 относятся больные на завершающей стадии заболевания, а к классу больные2 – на начальной. Ранее такое разбиение больных не проводилось. Таким образом, обучение нейронной сети решению прикладной задачи поставило перед исследователем содержательный вопрос, позволивший получить новое знание о предметной области.
Подводя итоги этого раздела, можно сказать, что, используя метод двойственности в обучении нейронных сетей можно:
- Обучать сеть решению задачи.
- Подбирать входные данные так, чтобы на выходе нейронной сети был заданный ответ.
- Ставить вопросы о соответствии входных данных задачника постановке нейросетевой задачи.
Задача обучения сети
С точки зрения математики, задача обучения нейронной сети является задачей минимизации множества функций многих переменных. Речь идет именно о неструктурированном множестве функций, зависящих от одних и тех же переменных. Под переменными понимаются обучаемые параметры сети, а под функциями – оценки решения сетью отдельных примеров. Очевидно, что сформулированная выше задача является как минимум трудно разрешимой, а часто и просто некорректной.
Основная проблема состоит в том, что при оптимизации первой функции, значения других функций не контролируются. И наоборот, при оптимизации всех других функций не контролируется значение первой функции. Если обучение устроено по циклу – сначала оптимизация первой функции, потом второй и т.д., то после завершения цикла значение любой из функций может оказаться не меньше, а больше чем до начала обучения. Такой подход к обучению нейронных сетей привел к появлению различных методов «коррекции» данной трудности. Так, например, появилось правило, что нельзя «сильно» оптимизировать оценку отдельного примера, для того, чтобы при оптимизации сеть «не сильно» забывала остальные примеры. Возникли различные правила «правильного» перебора примеров и т.д. Наиболее ярким примером такого правила является случайный перебор примеров, рекомендованный для обучения сетей, обучаемых без учителя (сетей Кохонена [131, 132]). Однако все эти правила не гарантировали быстрого достижения результата. Более того, часто результат вообще не достигался за обозримое время.
Альтернативой всем правилам «малой оптимизации» и «правильного перебора примеров» является выработка единой функции оценки всего обучающего множества. Правила построения оценки обучающего множества из оценок отдельных примеров приведены в главе «Оценка и интерпретатор ответа».
В случае использования оценки обучающего множества, математическая интерпретация задачи приобретает классический вид задачи минимизации функции в пространстве многих переменных. Для этой классической задачи существует множество известных методов решения [48, 104, 143]. Особенностью обучения нейронных сетей является их способность быстро вычислять градиент функции оценки. Под быстро, понимается тот факт, что на вычисления градиента тратится всего в два-три раза больше времени, чем на вычисление самой функции. Именно этот факт делает градиентные методы наиболее полезными при обучении нейронных сетей. Большая размерность пространства обучаемых параметров нейронной сети (102-106) делает практически неприменимыми все методы, явно использующие матрицу вторых производных.
Описание алгоритмов обучения
Все алгоритмы обучения сетей методом обратного распространения ошибки опираются на способность сети вычислять градиент функции ошибки по обучающим параметрам. Даже правило Хебба использует вектор псевдоградиента, вычисляемый сетью при использовании зеркального порогового элемента (см. раздел «Пороговый элемент» главы «Описание нейронных сетей»). Таким образом, акт обучения состоит из вычисления градиента и собственно обучения сети (модификации параметров сети). Однако, существует множество не градиентных методов обучения, таких, как метод покоординатного спуска, метод случайного поиска и целое семейство методов Монте-Карло. Все эти методы могут использоваться при обучении нейронных сетей, хотя, как правило, они менее эффективны, чем градиентные методы. Некоторые варианты методов обучения описаны далее в этой главе.
Поскольку обучение двойственных сетей с точки зрения используемого математического аппарата эквивалентно задаче многомерной оптимизации, то в данной главе рассмотрены только несколько методов обучения, наиболее используемых при обучении сетей. Более полное представление о методах оптимизации, допускающих использование в обучении нейронных сетей, можно получить из книг по методам оптимизации (см. например [48, 104, 143]).
Краткий обзор макрокоманд учителя
При описании методов используется набор макросов, приведенный в табл. 2. В табл. 2 дано пояснение выполняемых макросами действий. Все макрокоманды могут оперировать с данными как пространства параметров, так и пространства входных сигналов сети. В первой части главы полагается, что объект обучения установлен заранее. В макросах используются понятия и аргументы, приведенные в табл. 1. Список макрокоманд приведен в табл. 2.
Таблица 1
Понятия и аргументы макрокоманд, используемых при описании учителя
| Название |
Смысл |
| Точка |
Точка в пространстве параметров или входных сигналов. Аналогична вектору. |
| Вектор |
Вектор в пространстве параметров или входных сигналов. Аналогичен точке. |
| Вектор_минимумов |
Вектор минимальных значений параметров или входных сигналов. |
| Вектор_максимумов |
Вектор максимальных значений параметров или входных сигналов. |
| Указатель_на_вектор |
Адрес вектора. Используется для передачи векторов в макрокоманды. |
| Пустой_указатель |
Указатель на отсутствующий вектор. |
При описании методов обучения все аргументы имеют тип, определяемый типом аргумента макрокоманды. Если в описании макрокоманды в табл. 2 тип аргумента не соответствует ни одному из типов, приведенных в табл. 1, то эти аргументы имеют числовой тип.
Таблица 2
Список макрокоманд, используемых для описания учителя
| Название |
Аргументы (типы) |
Выполняемые действия |
| Модификация_вектора |
Указатель_на_вектор
Старый_Шаг
Новый_Шаг |
Генерирует запрос на модификацию вектора (см. раздел «Провести обучение (Modify)»). |
| Вычислить_градиент |
|
Вычисляет градиент функции оценки. |
| Установить_параметры |
Указатель_на_вектор |
Скопировать вектор, указанный в аргументе, в текущий вектор. |
| Создать_вектор |
Указатель_на_вектор |
Создает экземпляр вектора с неопределенными значениями. Адрес вектора помещается в аргумент. |
| Освободить_вектор |
Указатель_на_вектор |
Освобождает память занятую вектором, расположенным по адресу Указатель_на_вектор. |
| Случайный_вектор |
Указатель_на_вектор |
В векторе, на который указывает Указатель_на_вектор, генерируется вектор, каждая из координат которого является случайной величиной, равномерно распределенной на интервале между значениями соответствующих координат векторов Вектор_минимумов и Вектор_максимумов. |
| Оптимизация_шага |
Указатель_на_вектор
Начальный_Шаг |
Производит подбор оптимального шага (см. рис. 3). |
| Сохранить_вектор |
Указатель_на_вектор |
Скопировать текущий вектор в вектор, указанный в аргументе. |
| Вычислить_оценку |
Оценка |
Вычисляет оценку текущего вектора. Вычисленную величину складывает в аргумент Оценка. |
Неградиентные методы обучения
Среди неградиентных методов рассмотрим следующие методы, каждый из которых является представителем целого семейства методов оптимизации:
- Метод случайной стрельбы (представитель семейства методов Монте-Карло).
- Метод покоординатного спуска (псевдоградиентный метод).
- Метод случайного поиска (псевдоградиентный метод).
- Метод Нелдера-Мида.
Метод случайной стрельбы
1. Создать_вектор В1
2. Создать_вектор В2
3. Вычислить_оценку О1
4. Сохранить_вктор В1
5. Установить_параметры В1
6. Случайный_вектор В2
7. Модификация_вектора В2, 0, 1
8. Вычислить_оценку О2
9. Если О2<О1 то переход к шагу 11
10. Переход к шагу 5
11. О1=О2
12. Переход к шагу 4
13. Установить_параметры В1
14. Освободить_вектор В1
15. Освободить_вектор В2
Рис. 1. Простейший алгоритм метода случайной стрельбы |
Идея метода случайной стрельбы состоит в генерации большой последовательности случайных точек и вычисления оценки в каждой из них. При достаточной длине последовательности минимум будет найден. Запись этой процедуры на макроязыке приведена на рис. 1
Остановка данной процедуры производится по команде пользователя или при выполнении условия, что О1 стало меньше некоторой заданной величины. Существует огромное разнообразие модификаций этого метода. Наиболее простой является метод случайной стрельбы с уменьшением радиуса. Пример процедуры, реализующей этот метод, приведен на рис. 2. В этом методе есть два параметра, задаваемых пользователем:
Число_попыток – число неудачных пробных генераций вектора при одном радиусе.
Минимальный_радиус – минимальное значение радиуса, при котором продолжает работать алгоритм.
Идея этого метода состоит в следующем. Зададимся начальным состоянием вектора параметров. Новый вектор параметров будем искать как сумму начального и случайного, умноженного на радиус, векторов. Если после Число_попыток случайных генераций не произошло уменьшения оценки, то уменьшаем радиус. Если произошло уменьшение оценки, то полученный вектор объявляем начальным и продолжаем процедуру с тем же шагом. Важно, чтобы последовательность уменьшающихся радиусов образовывала расходящийся ряд. Примером такой последовательности может служить использованный в примере на рис. 2 ряд 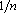 . .

Рис. 2. Алгоритм метода случайной стрельбы с уменьшением радиуса |
Отмечен ряд случаев, когда метод случайной стрельбы с уменьшением радиуса работает быстрее градиентных методов, но обычно это не так.
Метод покоординатного спуска
Идея этого метода состоит в том, что если в задаче сложно или долго вычислять градиент, то можно построить вектор, обладающий приблизительно теми же свойствами, что и градиент следующим путем. Даем малое положительное приращение первой координате вектора. Если оценка при этом увеличилась, то пробуем отрицательное приращение. Далее так же поступаем со всеми остальными координатами. В результате получаем вектор, в направлении которого оценка убывает. Для вычисления такого вектора потребуется, как минимум, столько вычислений функции оценки, сколько координат у вектора. В худшем случае потребуется в два раза большее число вычислений функции оценки. Время же необходимое для вычисления градиента в случае использования двойственных сетей можно оценить как 2-3 вычисления функции оценки. Таким образом, учитывая способность двойственных сетей быстро вычислять градиент, можно сделать вывод о нецелесообразности применения метода покоординатного спуска в обучении нейронных сетей.
Подбор оптимального шага
Данный раздел посвящен описанию макрокоманды Оптимизация_Шага. Эта макрокоманда часто используется в описании процедур обучения и не столь очевидна как другие макрокоманды. Поэтому ее текст приведен на рис. 3. Идея подбора оптимального шага состоит в том, что при наличии направления в котором производится спуск (изменение параметров) задача многомерной оптимизации в пространстве параметров сводится к одномерной оптимизации – подбору шага. Пусть заданы начальный шаг (Ш2) и направление спуска (антиградиент или случайное) (Н). Тогда вычислим величину О1 – оценку в текущей точке пространства параметров. Изменив параметры на вектор направления, умноженный на величину пробного шага, вычислим величину оценки в новой точке – О2. Если О2 оказалось меньше либо равно О1, то увеличиваем шаг и снова вычисляем оценку. Продолжаем эту процедуру до тех пор, пока не получится оценка, большая предыдущей. Зная три последних значения величины шага и оценки, используем квадратичную оптимизацию – по трем точкам построим параболу и следующий шаг сделаем в вершину параболы. После нескольких шагов квадратичной оптимизации получаем приближенное значение оптимального шага.

Рис. 3. Алгоритм оптимизации шага |
Если после первого пробного шага получилось О2 большее О1, то уменьшаем шаг до тех пор, пока не получим оценку, меньше чем О1. После этого производим квадратичную оптимизацию.
Метод случайного поиска
Этот метод похож на метод случайной стрельбы с уменьшением радиуса, однако в его основе лежит другая идея – сгенерируем случайный вектор и будем использовать его вместо градиента. Этот метод использует одномерную оптимизацию – подбор шага. Одномерная оптимизация описана в разделе «Одномерная оптимизация». Процедура случайного поиска приведена на рис. 4. В этом методе есть два параметра, задаваемых пользователем.
1. Создать_вектор Н
2. Число_Смен_Радиуса=1
3. Попытка=0
4. Радиус=1/ Число_Смен_Радиуса
5. Случайный_вектор Н
6. Оптимизация шага Н Радиус
7. Попытка=Попытка+1
8. Если Радиус=0 то Попытка=0
9. Если Попытка<=Число_попыток то переход к шагу 4
10. Число_Смен_Радиуса= Число_Смен_Радиуса+1
11. Радиус=1/ Число_Смен_Радиуса
12. Если Радиус>= Минимальный_радиус то переход к шагу 3
13. Освободить_вектор Н
Рис. 4. Алгоритм метода случайного поиска |
Число_попыток – число неудачных пробных генераций вектора при одном радиусе.
Минимальный_радиус – минимальное значение радиуса, при котором продолжает работать алгоритм.
Идея этого метода состоит в следующем. Зададимся начальным состоянием вектора параметров. Новый вектор параметров будем искать как сумму начального и случайного, умноженного на радиус, векторов. Если после Число_попыток случайных генераций не произошло уменьшения оценки, то уменьшаем радиус. Если произошло уменьшение оценки, то полученный вектор объявляем начальным и продолжаем процедуру с тем же шагом. Важно, чтобы последовательность уменьшающихся радиусов образовывала расходящийся ряд. Примером такой последовательности может служить использованный в примере на рис. 4 ряд .
Метод Нелдера-Мида
Этот метод является одним из наиболее быстрых и наиболее надежных не градиентных методов многомерной оптимизации. Идея этого метода состоит в следующем. В пространстве оптимизируемых параметров генерируется случайная точка. Затем строится n-мерный симплекс с центром в этой точке, и длиной стороны l. Далее в каждой из вершин симплекса вычисляется значение оценки. Выбирается вершина с наибольшей оценкой. Вычисляется центр тяжести остальных n вершин. Проводится оптимизация шага в направлении от наихудшей вершины к центру тяжести остальных вершин. Эта процедура повторяется до тех пор, пока не окажется, что оптимизация не изменяет положения вершины. После этого выбирается вершина с наилучшей оценкой и вокруг нее снова строится симплекс с меньшими размерами (например 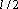 ). Процедура продолжается до тех пор, пока размер симплекса, который необходимо построить, не окажется меньше требуемой точности. ). Процедура продолжается до тех пор, пока размер симплекса, который необходимо построить, не окажется меньше требуемой точности.
Однако, несмотря на свою надежность, применение этого метода к обучению нейронных сетей затруднено большой размерностью пространства параметров.
Градиентные методы обучения
Изучению градиентных методов обучения нейронных сетей посвящено множество работ [47, 65, 90] (сослаться на все работы по этой теме не представляется возможным, поэтому дана ссылка на работы, где эта тема исследована наиболее детально). Кроме того, существует множество публикаций, посвященных градиентным методам поиска минимума функции [48, 104] (как и в предыдущем случае, ссылки даны только на две работы, которые показались наиболее удачными). Данный раздел не претендует на какую-либо полноту рассмотрения градиентных методов поиска минимума. В нем приведены только несколько методов, применявшихся в работе группой «НейроКомп». Все градиентные методы объединены использованием градиента как основы для вычисления направления спуска.
Метод наискорейшего спуска
1. Вычислить_оценку О2
2. О1=О2
3. Вычислить_градиент
4. Оптимизация шага Пустой_указатель Шаг
5. Вычислить_оценку О2
6. Если О1-О2<Точность то переход к шагу 2
Рис. 5. Метод наискорейшего спуска |
Наиболее известным среди градиентных методов является метод наискорейшего спуска. Идея этого метода проста: поскольку вектор градиента указывает направление наискорейшего возрастания функции, то минимум следует искать в обратном направлении. Последовательность действий приведена на рис. 5.
Этот метод работает, как правило, на порядок быстрее методов случайного поиска. Он имеет два параметра – Точность, показывающий, что если изменение оценки за шаг метода меньше чем Точность, то обучение останавливается; Шаг – начальный шаг для оптимизации шага. Заметим, что шаг постоянно изменяется в ходе оптимизации шага.
align=center а)
б)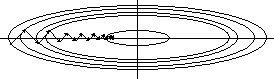
в)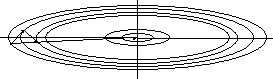
Рис. 6. Траектории спуска при различных конфигурациях окрестности минимума и разных методах оптимизации. |
Остановимся на основных недостатках этого метода. Во-первых, эти методом находится тот минимум, в область притяжения которого попадет начальная точка. Этот минимум может не быть глобальным. Существует несколько способов выхода из этого положения. Наиболее простой и действенный – случайное изменение параметров с дальнейшим повторным обучение методом наискорейшего спуска. Как правило, этот метод позволяет за несколько циклов обучения с последующим случайным изменением параметров найти глобальный минимум.
Вторым серьезным недостатком метода наискорейшего спуска является его чувствительность к форме окрестности минимума. На рис. 6а проиллюстрирована траектория спуска при использовании метода наискорейшего спуска, в случае, если в окрестности минимума линии уровня функции оценки являются кругами (рассматривается двумерный случай). В этом случае минимум достигается за один шаг. На рис. 6б приведена траектория метода наискорейшего спуска в случае эллиптических линий уровня. Видно, что в этой ситуации за один шаг минимум достигается только из точек, расположенных на осях эллипсов. Из любой другой точки спуск будет происходить по ломаной, каждое звено которой ортогонально к соседним звеньям, а длина звеньев убывает. Легко показать что для точного достижения минимума потребуется бесконечное число шагов метода градиентного спуска. Этот эффект получил название овражного, а методы оптимизации, позволяющие бороться с этим эффектом – антиовражных.
kParTan
1. Создать_вектор В1
2. Создать_вектор В2
3. Шаг=1
4. Вычислить_оценку О2
5. Сохранить_вектор В1
6. О1=О2
7. N=0
8. Вычислить_градиент
9. Оптимизация_шага Пустой_указатель Шаг
10. N=N+1
11. Если N<k то переход к шагу 8
12. Сохранить_вектор В2
13. В2=В2-В1
14. ШагParTan=1
15. Оптимизация шага В2 ШагParTan
16. Вычислить_оценку О2
17. Если О1-О2<Точность то переход к шагу 5
Рис. 7. Метод kParTan |
Одним из простейших антиовражных методов является метод kParTan. Идея метода состоит в том, чтобы запомнить начальную точку, затем выполнить k шагов оптимизации по методу наискорейшего спуска, затем сделать шаг оптимизации по направлению из начальной точки в конечную. Описание метода приведено на рис 7. На рис 6в приведен один шаг оптимизации по методу 2ParTan. Видно, что после шага вдоль направления из первой точки в третью траектория спуска привела в минимум. К сожалению, это верно только для двумерного случая. В многомерном случае направление kParTan не ведет прямо в точку минимума, но спуск в этом направлении, как правило, приводит в окрестность минимума меньшего радиуса, чем при еще одном шаге метода наискорейшего спуска (см. рис. 6б). Кроме того, следует отметить, что для выполнения третьего шага не потребовалось вычислять градиент, что экономит время при численной оптимизации.
Квазиньютоновские методы
Существует большое семейство квазиньютоновских методов, позволяющих на каждом шаге проводить минимизацию в направлении минимума квадратичной формы. Идея этих методов состоит в том, что функция оценки приближается квадратичной формой. Зная квадратичную форму, можно вычислить ее минимум и проводить оптимизацию шага в направлении этого минимума. Одним из наиболее часто используемых методов из семейства одношаговых квазиньютоновских методов является BFGS метод. Этот метод хорошо зарекомендовал себя при обучении нейронных сетей (см. [29]). Подробно ознакомиться с методом BFGS и другими квазиньютоновскими методами можно в работе [48].
Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
|