|
Орехов Антон Игоревич
Исходные тексты используемых программ:
- в кодировке КОИ-8Р ~5.5 кб
- в кодировке Windows ~5.5 кб
Оглавление
Mozart
Mozart - современная система программирования основанная на Oz. Это язык сверхвысокого уровня, декларативный. Включает в себя множество парадигм и принципов в едином дизайне. В том числе: процедурное программирование, ООП, ФП, ЛП, dataflow, программирование в ограничениях и Н-модели. При этом синтаксис прост, программы хорошо читаются.
Получить подробную информацию о языке и скачать версию интерпретатора вы можете, используя ресурс: http://www.mozart-oz.org/
При подготовке данной статье использовалась версия Mozart 1.3.1.
При просмотре исходных текстов, прилагаемых к статье, настройте в текстовом редакторе величину табуляции - 4 пробела.
Логическое программирование
Все существующие языки программирования основаны на некоторых общих принципах - парадигмах.
Наиболее распространенные парадигмы:
- Процедурное программирование. Память вычислительной машины условно делится на две части. В одной хранятся данные в виде переменных. В другой - команды, которые изменяют содержимое переменных. Современные процедурные языки включают различные средства структурированного программирования, что помогает упорядочить управляющие связи в программе.
- Объектно-ориентированное программирование (ООП). Процедуры (методы) и переменные (атрибуты) группируются в т.н. классы. ООП языки позволяют упорядочить связи по данным, т.к. доступ к переменным может выполняться явно путем вызова соответствующих методов. Сами методы чаще всего описываются в процедурном стиле.
- Функциональное программирование (ФП). Программа рассматривается, как суперпозиция функций. Переменные отсутствуют, нет изменяемых объектов. Такой подход делает программирование ближе к математической записи задачи. Программы как правило короче и содержат меньшее кол-во ошибок, чем в императивном (процедурном) стиле.
Пример: Лисп, Хэскелл, OCAML.
- Логическое программирование (ЛП). Основано на формальной логике. Программа задается как набор логич. утверждений. Путем применения операций унификации (сопоставления) и редукции (преобразования, упрощения) система находит решение задачи. Искомые величины задаются в виде переменных в логических отношениях и запросах. (Переменная здесь не есть "переменная-ячейка памяти" в понимании процедурного программирования. В ЛП, аналогично функциональным языкам, переменная всего лишь символическое обозначение некой сущности. Значение переменной не может изменяться: оно либо найдено, либо нет. Понятие переменной в ФП и ЛП языках более точно соответствует понятию переменной в математике.)
Существуют и другие, более современные подходы в ЛП. Один из них: программирование в ограничениях. Задача формулируется как набор логических ограничений на условия. В таких языках применяется расширенное понятие переменной: недоопределенная переменная. Она имеет конкретное (возможно неизвестное на данном этапе) значение - денотат. И некую область значений, в которую денотат входит.
Пример: Пролог, Меркурий, Моцарт, CHIP.
Языки ФП и ЛП относят к программированию сверхвысокого уровня, декларативному. Т.е. в программе может не задаваться алгоритм решения в явном виде. Исходный текст ближе к естественной математической записи условий.
Синтаксис и особенности
Некоторые особенности синтаксиса Mozart, чтобы было проще разобраться в приводимых ниже примерах. (За более подробной информацией о синтаксисе и семантике языка лучше обратиться к стандартной документации.)
Коментарии в Oz задаются символом %.
Отступы можно делать пробелами или табуляцией. Желательно, чтобы величина отступа была 3 или 4 символа.
Имена переменных, процедур и функций начинаются с большой буквы. Можно использовать любую строку символов, ее надо ограничить символом "`" (это не кавычка!). Например:
A = 2
`mega !` = 3
`SuPeR!!! :-)` = A * `mega !`
Имена атомов (атом - неделимый элемент языка) начинаются с маленькой буквы. Можно использовать любую строку символов, ограничив ее "'" (а вот это кавычка :-) ).
functor % Функтор - программный модуль
import % Импортируем необходимые библиотеки и модули
Application(exit)
QTk at 'x-oz://system/wp/QTk.ozf'
Browser(browse:Browse)
Explorer
export
% Если необходимо, экспортируем объекты из модуля
define % начало программы
...
end
Функторы могут быть вложенными.
Процедура определяется так:
proc {Test X Y Z}
...
end
Мы задаем имя процедуры (Test) и перечисляем параметры (X, Y, Z). В ЛП нет различий между входными параметрами и выходными. Для удобства можно пометить выходные параметры знаком вопроса: proc {Test X Y ?Z}. Это не влияет на вычисления.
Вызов процедуры записывается в фигурных скобках:
{Test 5 A Var2}
Можно применять процедуру подобно функции. Если не указывать в вызове последний аргумент, он используется как возвращаемое значение:
Ret = {Test 3.57 S}
Также бывают анонимные процедуры, их можно определять внутри различных выражений и конструкций:
P = proc {$ X Y} Y = 2 * X end
Эта запись полностью эквивалентна:
proc {P X Y} Y = 2 * X end
Функция определяется:
fun {MyFun X Y Z}
...
Ret
end
Что эквивалентно:
proc {MyFun X Y Z Ret}
...
Ret = ...
end
Ячейки памяти и переменные
В ФП и ЛП отсутствуют переменные в понимании процедурного программирования. Переменная в математическом смысле есть не некая ячейка памяти, а лишь символическое обозначение некой сущности. Значение переменной может быть известно точно, известно приблизительно или не известно. Но меняться со временем оно не может!
Пример:
X = 2
...
X = 3
При попытке трансляции такой программы, будет выдано сообщение об ошибке. Первая строка означает: X есть 2. Затем мы написали: X является числом 3. Эти два факта противоречат друг другу! Таким образом "переменные" на самом деле "постоянные". Мы будем применять слово переменная лишь потому, что это привычный термин. Но всегда надо помнить о семантике переменных в ЛП.
Процедурное программирование удобно для некоторых задач. Например операции ввода /вывода соответствуют последовательной-императивной модели выполнения. Для решения некоторых задач удобно применять и ячейки памяти, для временного хранения некой информации. Например в ООП переменные используются для запоминания состояния объектов.
Oz позволяет использовать ячейки памяти (Cell).
X = {NewCell 0} % Мы создали ячейку памяти, инициировали ее значением 0 и прикрепили к переменной X
X := 3 % Мы изменили значение ячейки памяти X (оператор ":=" )
Z = @X % Чтобы считать значение ячейки, надо поставить символ "@" перед переменной
{Exchange X A B} % возвращает текущее значение ячейки X в A и присваивает ячейке значение из B
Область видимости объектов
Переменная должна быть сперва объявлена.
X Y
Мы объявили две переменные X и Y. Они еще не имеют конкретного значения. Будем считать, что их значение не известно на данной момент времени.
X = 3
Теперь X обозначает число 3.
declare
Объявленные переменные глобально видны от данного места в программе и ниже.
declare X Y in
local
Переменные, доступные в ограниченной области. Локальные переменные.
local X Y in
...
end
Во многих случаях, например в процедурах и функциях, можно не указывать ключевые слова local и end.
proc {MyProc A B R}
X Y in
...
end
Действует механизм вложенных областей видимости.
local X in
X = 3
{Browse X}
local X in
X = 7
{Browse X}
end
{Browse X}
end
Выдаст: 3, 7, 3
Передача сообщений, порты
Порт (Port) - реализация механизма передачи сообщений в Oz
P S
P = {Port S}
Мы создали порт P, привязанный к потоку данных S. S - фактически очередь сообщений. Принимающая сторона должна считывать сообщения из S и отрабатывать их. Через переменную P посылаем сообщения.
{Send P 'Hello!'}
Поток в Oz запускается конструкцией thread ... end. Все, что стоит внутри конструкции, выполняется в отдельной нити. Это очень удобно. Например:
это основной поток
thread
здесь выполняем действия, параллельно с основным потоком
end
thread
и еще один поток
thread
ничто не мешает делать thread вложенными :-)
end
end
Вот так :-)
(thread запускает т.н. легкие потоки - в одном физическом)
Подробнее о параллельном программировании в Mozart: "Приемы параллельного программирования в Mozart 1.3.1".
Программист, создающий программу, где различные действия производятся параллельно в разных процессах и потоках, сталкивается с проблемой готовности данных. Допустим, один процесс (Процесс1) присваивает переменной A значение 7, а другой процесс (Процесс2) использует значение переменной A для каких-либо вычислений. Если Процесс2 обратится к переменной A, когда Процесс1 еще не записал значение, произойдет логическая ошибка в программе. Такие ошибки могут привести к непредсказуемым последствиям. В одних трансляторах произойдет сбой при обращении к несуществующему объекту. В других программа будет выполняться, но Процесс2 считает "мусорное" или нулевое значение переменной. Чтобы решить эти проблемы, была разработана концепция dataflow. Виртуальная машина транстлятора следит за состоянием переменных и автоматически контроллирует выполнение процессов и потоков. Переменная (на самом деле это не переменные - они не изменяемы) в Oz может быть объявленной, без определенного значения - свободная переменная.
Например:
local A in
...
Мы объявили переменную A, но значение она еще не получила.
Затем, мы может связать имя A с любым объектом:
A = 7
Теперь A - символическая ссылка на числовой объект, значение 7. Механизм dataflow следит за тем, связана переменная или свободна.
local A in
thread
{Time.delay 5000}
A = 7
end
{Wait A}
В точке {Wait A} программа приостановится и будет ждать, пока переменная A не будет связана с конкретным значением. Dataflow может использоваться и более широко (и менее явно).
for Msg in S do
...
end
Поток считывает сообщения из S. Причем, если следующее сообщение еще не готово, поток будет автоматически приостановлен. Как только данные будут доступны, поток продолжит работу.
Общий принцип упрвляющих потоков данных (dataflow): если запрашиваются данные, еще не вычисленные - поток переходит в режим ожидания. Как только значение будет найдено и присоединено к переменной - поток продолжит работу.
В стандартную библиотеку Mozart входят удобные инструменты для вывода результатов и исследования работы программ.
Browser
Средство для вывода результатов. Для использования необходимо импортировать:
import
Browser(browse:Browse)
В программе:
{Browse 2 * 2}
{Browse X}
Откроется окно с результатами.
Explorer
Вывод результатов логического поиска.
import
Explorer
В программе:
{Explorer.all Question}
Построение дерева поиска и вывод результатов в графическом окне.
Трансляция и запуск программ
С Mozart поставляется среда разработки на основе EMacs. Но можно пользоваться любым другим редактором, а трансляцию и отладку запускать из командной строки. (предпочитаю VIM) Oz - интерпретируемый язык, виртуальная машина выполняет файлы в байт-код формате.
Трансляция:
ozc -c test.oz
Будет выполнена компиляция программы test.oz. Созданный файл test.ozf можно непосредственно запускать через интерпретатор.
Детерминированное ЛП
Логические утверждения можно задать таким образом, чтобы полностью и однозначно описать требуемый путь решения. Такой подход программирования называется детерменированным. Другими словами, программист знает алгоритм решения и записывает его в однозначной форме.
Простейший вариант - использование конструкции if ... then, имеющейся в большинстве языков программирования.
case E
of Pattern_1 then S1
[] Pattern_2 then S2
[] ...
else S end
Проверяет E на соответствие одному из шаблонов Pattern. При этом можно неявно вводить переменные, они будут доступны в контексте соответствующего выражения S.
Case выполняется следующим образом. Шаблоны Pattern по очереди проверяются на соответствие выражению E. Сопоставление шаблона происходит слева направо, без глубокого анализа. Как только сравнение пройдет успешно, будет выполнено соответствующее выражение S. Если все шаблоны не подходят, будет выполнено выражение else. В случае отсутствия последнего, генерируется исключение.
Для примера, определим функцию Append при помощи case конструкции. Append присоединяет список L2 к списку L1 и возвращает результат L3.
proc {Append L1 L2 L3}
case L1
of nil then L2=L3
[] X|T1 then L3=X|{Append T1 L2}
end
end
{Browse {Append [1 2 3] [4 5 6]}}
Или в функциональном стиле:
fun {Append L1 L2}
case L1 of nil then L2
[] X|T1 then X|{Append T1 L2}
end
end
or
G1 then S1
[] G2 then S2
...
[] GN then SN
end
На момент выполнения запроса or, существует некоторое пространство вычислений SP.
-
Текущий поток выполнения приостанавливается.
-
Создается N пространств для SP1, ... , SPN и N потоков для выполнения G1, ... , GN.
-
Выполнение основного потока останавливается, пока не будет удачно определено хотя бы одно дочернее пространство
-
Если все дочерние потоки возвращают неудачу, то в главном потоке возбуждается исключение
-
Если найдено удачное решение, то происходит слияние пространства объектов дочернего и основного потока. Только один поток может быть выбран в качестве результата.
Элемент or позволяет в чисто логическом стиле программировать алгоритмы, где вычисления синхронизированы определенными условиями.
proc {Ints N Xs}
or N = 0 Xs = nil
[] Xr in
N > 0 = true Xs = N|Xr
{Ints N-1 Xr}
end
end
local
proc {Sum3 Xs N R}
or Xs = nil R = N
[] X|Xr = Xs in
{Sum3 Xr X+N R}
end
end
in proc {Sum Xs R} {Sum3 Xs 0 R} end
end
local N S R in
thread {Ints N S} end
thread {Sum S {Browse}} end
N = 1000
end
Поток, выполняющий Ints, приостанавливается пока не будет определено N. Точно также Sum3 будет ждать, пока не будет создан список S. Элементы списка будут генерироваться последовательно, при этом Sum3 может приостанавливаться и возобновлять работу. Вычисления стартуют, как только в основном потоке будет присвоено: N = 1000. Таким образом лаконично определяются различные алгоритмы с синхронизацией.
cond X1 ... XN in S0 then S1 else S2 end
Допустим, основной поток выполняется в контексте (пространстве) SP.
-
Основной поток приостанавливается
-
Создается пространство SP1 и дополнительный поток, который выполняет cond X1 ... XN in S0
-
Основной поток будет в режиме ожидания, пока не будет возвращено или отменено SP1. При этом надо следить, чтобы поток в SP1 не зациклился или не заблокировался.
-
Если SP1 отменяется, то родительский поток выполняет S2
-
Если пространство вычислений SP1 успешно создается, то происходит слияние с родительским SP. Затем, основной поток продолжает выполнение через S1.
Параллельная форма:
cond G1 then S1
[] G2 then S2
...
else SN end
При этом проверяются все G1 ... GN в произвольном порядке, возможно параллельно, в отдельных пространствах. Если одно из выражений Gk успешно, то основной поток продолжает выполнение через Sk. Если ни одно условие не выполнено, то вычисления переходят на SN. Если же else ветвь отсутствует - поток останавливается.
Эта конструкция (cond) - базовая для языков параллельного логического программирования. Такие языки называют логическими языками committed-choice (принятия решения).
Классический пример параллельного логического программирования. Процедура объединяет два потока данных в один выходной. Порядок элементов в выходном потоке зависит от времени прихода данных.
proc {Merge Xs Ys ?Zs}
cond
Xs = nil then Zs = Ys
[] Ys = nil then Zs = Xs
[] X Xr in Xs = X|Xr then Zr in
Zs = X|Zr {Merge Xr Ys Zr}
[] Y Yr in Ys = Y|Yr then Zr in
Zs = Y|Zr {Merge Xs Yr Zr}
end
end
На самом деле такой способ может быть не очень эффективным. Можно определить Merge в постоянном потоке:
proc {MMerge STs L}
C = {NewCell L}
proc {MM STs S E}
case STs
of ST|STr then M in
thread
{ForAll ST proc{$ X} ST1 in {Exchange C X|ST1 ST1} end}
M=S
end
{MM STr M E}
[] nil then skip
[] merge(STs1 STs2) then M in
thread {MM STs1 S M} end
{MM STs2 M E}
end
end
E
in
thread {MM STs unit E} end
thread if E==unit then L = nil end end
end
Но {Merge X Y Z} гораздо проще и читабельнее, чем {MMerge [X Y] Z}.
Недетерминированное ЛП и механизмы поиска
Для многих задач не существует известного эффективного алгоритма. В таких случаях решение удобнее программировать, применяя специальные методы ЛП.
Постановку задачи, с использованием механизмов поиска Oz можно описать так:
-
В виде процедур задаются логические условия, факты и ограничения. Специальными конструкциями языка можно задать точки выбора для построения дерева поиска.
-
Формируется процедура - запрос. Она обращается к базе знаний, содержащей условия задачи (1.). Запрос должен содержать один аргумент - в него и помещаются результаты (аргумент может быть сложной структурой данных).
-
Запускается механизм поиска решений. При этом можно задать режим поиска.
При поиске решений происходит определение верного направления движения по дереву возможных вариантов. Если текущая ветвь возвращает неудачу, то происходит откат на шаг вверх. И выбирается альтернативная ветвь. Для явного указания принятия решения на текущем этапе, применяют ключевые слова skip (логическая истина, удача) и fail (неудача, прервать, логическая ложь).
Если все сопоставления терпят неудачу, кроме одного. То выполнение продолжается по удачной ветви. В таком случае алгоритм детерминирован. Если же больше одного положительного сравнения с шаблоном, то создаются точки выбора (ветвления) и необходим механизм поиска для дальнейшего решения. В этом случае выполнение недетерминировано.
proc {Append L1 L2 L3}
dis
L1 = nil L2 = L3
[] X T1 T3 in
L1 = X|T1 L3 = X|T3 then
{Append T1 L2 T3}
end
end
Такая запись соответствует семантике выражений на языке Пролог:
append([], L2, L2).
append([X|T1], L2, [X|T3]) :- append(T1, L2, T3).
(Сравните такой вариант Append с детерминированным (гл. case))
Создадим запросы:
proc {Q1 X}
{Append [1 2 3] [4 5 6] X}
end
proc {Q2 X}
L1#L2 = X in
{Append L1 L2 [1 2 3 4 5 6]}
end
proc {Q3 X}
{Append X [4 5 6] [1 2 3 4 5 6]}
end
Теперь мы можем воспользоваться модулем поиска и получить ответы. (для этого необходимо импортировать Search)
{Browse {Search.base.all Q1}}
{Browse {Search.base.all Q2}}
{Browse {Search.base.all Q3}}
Результаты:
Q1: [[1 2 3 4 5 6]]
Q2: [nil#[1 2 3 4 5 6] [1]#[2 3 4 5 6] [1 2]#[3 4 5 6]
[1 2 3]#[4 5 6] [1 2 3 4]#[5 6] [1 2 3 4 5]#[6] [1 2 3 4 5 6]#nil]
Q3: [[1 2 3]]
Также мы может создать объект поиска и получать результаты по очереди (подобно тому, как это происходит в Прологе):
S = {New Search.object script(Q2)}
for I in 1..8 do
{Browse {S next($)}}
end
Каждый вызов next будет возвращать следующий результат. Когда все варианты будут найдены, будет возвращено nil.
[nil#[1 2 3 4 5 6]]
[[1]#[2 3 4 5 6]]
[[1 2]#[3 4 5 6]]
[[1 2 3]#[4 5 6]]
[[1 2 3 4]#[5 6]]
[[1 2 3 4 5]#[6]]
[[1 2 3 4 5 6]#nil]
nil
Отличается от dis тем, что сразу создает все точки ветвления. Без анализа - терпят сопоставления неудачу или нет.
Для примера:
proc {Append L1 L2 L3}
choice
L1 = nil L2 = L3
[] X T1 T3 in
L1 = X|T1 L3 = X|T3
{Append T1 L2 T3}
end
end
При помощи choice удобно задавать факты и отношения.
proc {Boss B E}
choice
B = sergey E = anton
[] B = sergey E = aleksey
[] B = sergey E = nikolay
[] B = anatoly E = sergey
[] B = ivan E = anatoly
end
end
Мы описали отношение: начальник-подчиненный. Каждая строка означает отдельное утверждение. Например: sergey начальник aleksey и т.д..
Зададим запросы:
{Browse {Search.base.all proc{$ X} {Boss X nikolay} end}}
% кто является непосредственным начальником Николая
Вывод:
[sergey]
Спросим, кто подчиняется Сергею
{Browse {Search.base.all proc{$ X} {Boss sergey X} end}}
Ответ:
[anton aleksey nikolay]
Добавим еще одну процедуру, чтобы узнать обо всех начальниках конкретного работника:
proc {Chief C E}
choice
{Boss C E}
[] X in {Boss C X} {Chief X E}
end
end
Запрос:
{Browse {Search.base.all proc {$ X} {Chief X anton} end}}
% все руководители Антона
Ответ:
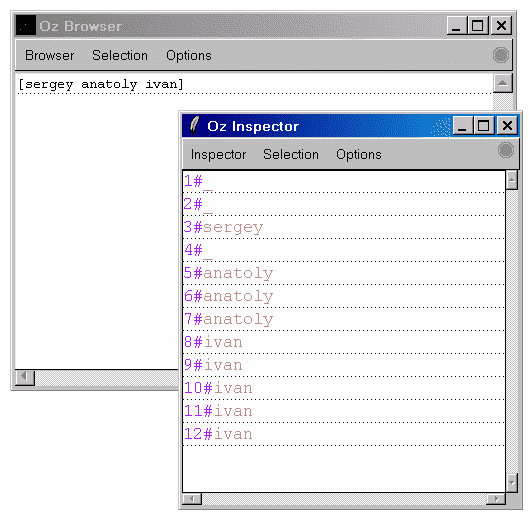
[sergey anatoly ivan]
Обратный запрос:
{Browse {Search.base.all proc {$ X} {Chief anatoly X} end}}
% все подчиненные Анатолия
Ответ:
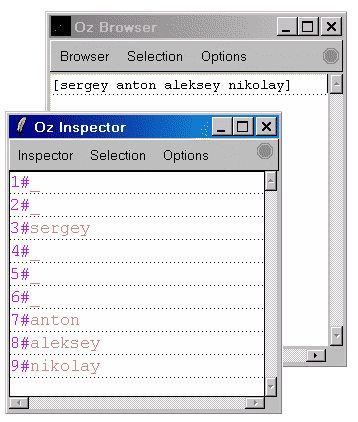
[sergey anton aleksey nikolay]
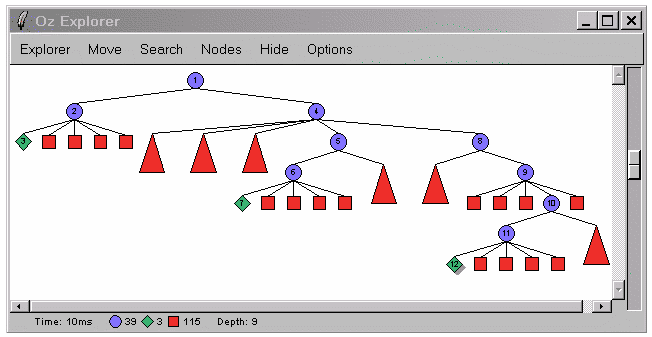
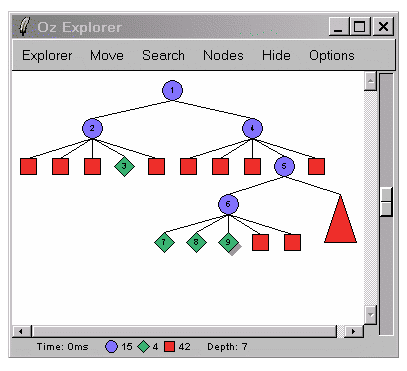
Диаграммы поиска для двух последних задач.
{Explorer.all proc {$ X} {Chief X anton} end}
Для обратной задачи:
{Explorer.all proc {$ X} {Chief anatoly X} end}
Eще одна задачка с использованием choice: подбор костюма (весьма веселого :-) ).
Цвета: приглушенные (soft): бежевый и кораловый; и яркие (hard): лиловый и охра.
Одежда: Рубашка (Shirt), Брюки (Pants), Носки (Socks).
Необходимо подобрать элементы одежды, чтобы цвета смежных элементов были контрастны. При этом все оттенки должны быть разными (в цирк готовимся? :-) ).
fun {Soft} choice beige [] coral end end
fun {Hard} choice mauve [] ochre end end
proc {Contrast C1 C2}
choice C1={Soft} C2={Hard} [] C1={Hard} C2={Soft} end
end
fun {Suit}
Shirt Pants Socks
in
{Contrast Shirt Pants}
{Contrast Pants Socks}
if Shirt==Socks then fail end
suit(Shirt Pants Socks)
end
{Browse {Search.base.all Suit}}
Результаты:
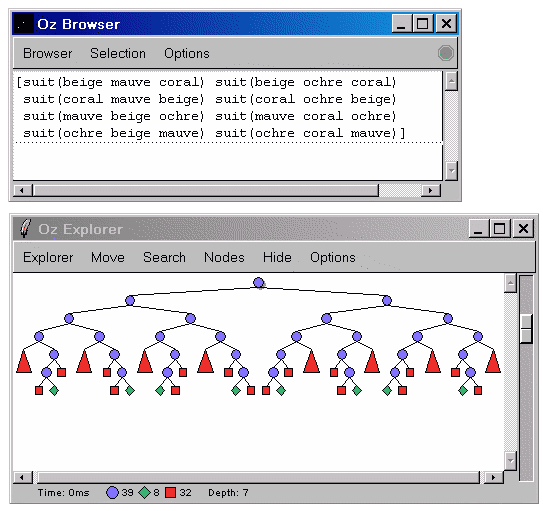
Программирование в ограничениях
Это одно из наиболее современных направлений в ЛП. Условие задачи вводится в программу, как система ограничений. Это могут быть логические утверждения, уравнения и т.п.. При этом используются недоопределенные переменные - Н-переменные. Такая переменная имеет некое значение (возможно неизвестное нам) - денотат. И интервал, в который денотат входит. К примеру, мы можем оценить возраст приблизительно: от 35 до 42. Или размер: от 1 до 1.5 м. Н-переменная должна иметь ограниченное число значений - это важно для правильной работы механизмов поиска. Поэтому во многих языках (и в Oz) Н-переменные целочисленные. На самом деле можно проецировать на интервал целых чисел любые дробные величины с заданной точностью.
Условия задачи в ограничениях необходимо оформить в виде процедуры одного аргумента. Этот аргумент может быть структурой данных, содержащей искомые переменные. В теле процедуры задаем набор правил, уравнений, отношений и т.д..
import
FD
% модуль поддержки средств программирования
% в ограничениях и Н-переменных (от Finite Domain)
...
define
...
proc {Question Root}
X Y Z in
Root = sol(x:X y:Y z:Z) % Структура, содержащая решение задачи
Root ::: 2#7 % Каждая Н-переменная имеет интервал значений: от 2х до 7.
X + Y <: 15 % условия задачи, заданные уравнениями
X * Y =: Z
{FD.distribute ff Root} % режим поиска ff (first fail)
end
{Browse {Search.base.all Question}}
Результаты:
[sol(x:2 y:2 z:4) sol(x:2 y:3 z:6) sol(x:3 y:2 z:6)]
Обратите внимание, что для записи ограничений применяются символы, заканчивающиеся двоеточием: '<:', '=:', '>=:' и т.д..
Н-переменную можно задать как:
- интервал ::: 2#7 от двух до семи
- список значений ::: [2 5 7]
- комбинация первых двух вариантов ::: [3 5 10#15 7 25#30]
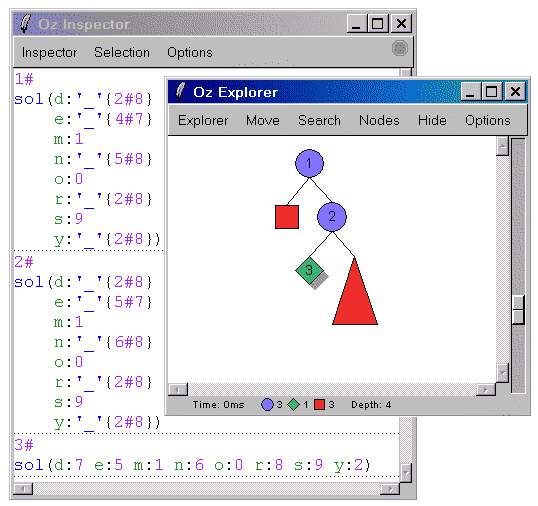
Решим логическую задачу. Вместо букв надо подставить цифры, чтобы равенство соблюдалось. Цифры не должны повторяться.
proc {Money Root}
S E N D M O R Y
in
Root = sol(s:S e:E n:N d:D m:M o:O r:R y:Y) % 1
Root ::: 0#9 % 2
{FD.distinct Root} % 3
S \=: 0 % 4
M \=: 0
1000*S + 100*E + 10*N + D % 5
+ 1000*M + 100*O + 10*R + E
=: 10000*M + 1000*O + 100*N + 10*E + Y
{FD.distribute ff Root}
end
{Browse {Search.base.all Money}}
{Explorer.all Money}
Условия задачи:
-
Используемый набор букв. Значение этих переменных и надо найти
-
Значения ограничены интервалом: от 0 до 9
-
Значения не повторяются
-
S и M не равны нулю. (иначе числа будут не 4х, а 3х значными)
-
Уравнение
Результаты:
[sol(d:7 e:5 m:1 n:6 o:0 r:8 s:9 y:2)]
Если программировать данную задачу методом перебора, то придется искать решение из более 40000 вариантов. Методы программирования в ограничениях и математические подходы Н-моделей позволяют более эффективно находить решение.
Решим более сложную задачу.
proc {Donald Root}
sol(a:A b:B d:D e:E g:G l:L n:N o:O r:R t:T) = Root
in
Root ::: 0#9
{FD.distinct Root}
D\=:0 R\=:0 G\=:0
100000*D + 10000*O + 1000*N + 100*A + 10*L + D
+ 100000*G + 10000*E + 1000*R + 100*A + 10*L + D
=: 100000*R + 10000*O + 1000*B + 100*E + 10*R + T
{FD.distribute ff Root}
end
{Browse {Search.base.all Donald}}
{Explorer.all Donald}
Ответ:
[sol(a:4 b:3 d:5 e:9 g:1 l:8 n:6 o:2 r:7 t:0)]
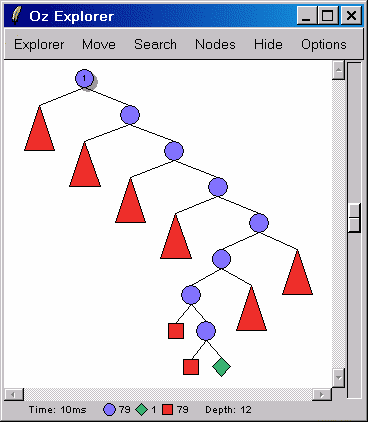
Попробуем провести поиск решения в более оптимальном для данного случая варианте - split:
{FD.distribute split Root}
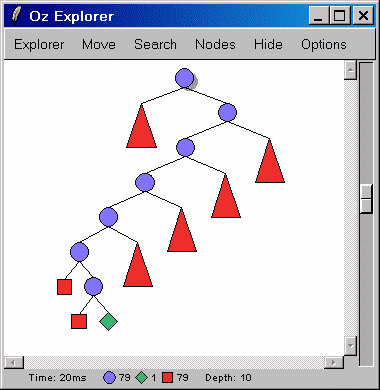
Потребовалось меньшее количество шагов.
Если мы изначально знаем, что решение одно. (или нам требуется найти хотя бы одно) Мы можем указать виртуальной машине искать только одно решение:
{Browse {Search.base.one Donald}}
{Explorer.one Donald}
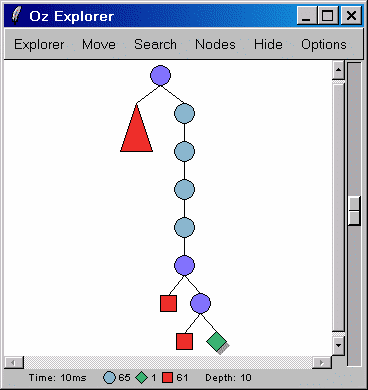
В таком случае не будет тратиться время на лишние действия, чтобы пройти все дерево решений.
Распределенные вычисления
Mozart содержит удобные средства распараллеливания вычислений по модели с распределенной памятью. Параллельные программы можно запускать на кластерах. Но и на SMP машинах Mozart будет выполняться довольно эффективно. Для того, чтобы указать системе вести распределенный поиск, достаточно передать методу Search.parallel список адресов компьютеров сети (естественно на каждой машине должен быть установлен интерпретатор Mozart и средства удаленного доступа, например SSH). Если применяется SMP компьютер, адрес должен быть 127.0.0.1.
FtrQuestion = functor % Задачу оформляем в отдельном модуле
import FD
export script:P % процедура с условиями задачи
define
proc {P Root}
A B C D E F G H I BC EF HI
in
Root = sol(a:A b:B c:C d:D e:E f:F g:G h:H i:I)
BC = {FD.decl} EF = {FD.decl} HI = {FD.decl}
Root ::: 1#9
{FD.distinct Root}
BC =: 10*B+C
EF =: 10*E+F
HI =: 10*H+I
A*EF*HI+D*BC*HI+G*BC*EF =: BC*EF*HI
{FD.distribute ff Root}
end
end
% Запускаем машину ЛП поиска в режиме распределенных вычислений:
% Мы задаем 'имя_пользователя@адрес_узла':число_процессоров# протокол_удаленного_доступа
E = {New Search.parallel init(
'cluster@127.0.0.1':1#ssh 'cluster@10.254.0.10':1#ssh
'cluster@10.254.0.14':1#ssh)}
X
{E all(FtrQuestion X)}
{Browse X}
Используя механизмы Search.parallel можно прозрачно задействовать любое кол-во процессоров для поиска решений.
Заключение
Нельзя объять необъятное. В данной статье опущены или рассмотрены недостаточно многие вопросы, связанные с логическим программированием в Mozart. Например, поверхностно и неполно освещены вопросы программирования в ограничениях и ленивые (lazy) вычисления. Также не затрагивалась такая тема, как анализ естественных языков при помощи ЛП. Не касались мы и теории. В следующем разделе будут даны некоторые ссылки на книги и статьи по Oz. На момент написания данной статьи, все они были доступны в Интернет. Легко найти их через поисковые машины.
Если вы только начинаете осваивать ЛП, то необходимо почитать книги и по теории логич. программирования.
Литература
При подготовке статьи использовались материалы и примеры из разных источников. В том числе:
1. Стандартная документация Mozart
2. Книга: "Concepts, Techniques, and Models of Computer Programming" PETER VAN ROY, SEIF HARIDI.
3. Статья: "Logic Programming in Oz with Mozart" Peter Van Roy
4. Статья: "Logic programming in the context of multiparadigm programming: the Oz experience" Peter Van Roy, Per Brand, Denys Duchier, Seif Haridi, Martin Heinz, Christian Schulte
5. "Concurrent Constraint Programming in Oz for Natural Language Processing" Denys Duchier, Claire Gardent and Joachim Niehren
6. "ПРОГРАММИРОВАНИЕ В ОГРАНИЧЕНИЯХ И НЕДООПРЕДЕЛЕННЫЕ МОДЕЛИ" А.С.Нариньяни, В.В. Телерман, Д.М. Ушаков, И.Е. Швецов
7. "Декларативное программирование" И.А.Дехтяренко
Также полезно изучать приемы логического программирования по книгам и статьям об языке Пролог.
|