|
Орехов Антон Игоревич
Исходные тексты используемых программ (в кодировке КОИ-8Р) ~5.5 кб
Оглавление
Mozart
Mozart это современная система
программирования основанная на Oz. Это язык сверхвысокого уровня,
декларативный. Включает в себя множество парадигм и принципов в
едином дизайне. В том числе: процедурное программирование, ООП, ФП,
ЛП, dataflow, программирование в ограничениях и Н-модели. При этом
синтаксис прост, программы хорошо читаются.
Механизмы параллелизма, встроенные в Oz основаны на двух концепциях:
-
Средства распределенных вычислений
- модель с разделенной памятью. Процессы независимы друг от друга.
Передача информации между процессами преимущественно через механизм
посылки сообщений. Каждый процесс получает в свое распоряжение
отдельный процессор и объем ОЗУ.
-
Легкие потоки. Средство
параллельного программирования, при этом физически процесс один.
Могут применяться для следующих целей:
-
когда требуется выполнять некоторые
действия параллельно (независимо). Объем вычислений при этом мал,
применять дополнительные процессоры не имеет смысла. Пример: один
поток обслуживает окна ГИП (Графический Интерфейс Пользователя),
второй ждет ответа на запрос к СУБД и т.п.
-
для написания алгоритмов с
применением параллелизма. Многие алгоритмы записываются в
параллельной форме гораздо естественнее и компактнее, чем в
последовательной.
-
для равномерной загрузки ЦП.
Однопоточная программа может неравномерно использовать мощности
процессора. В некоторые моменты времени происходит ожидание реакции
пользователя или ответа на запрос к другой программе. В таких случаях
процессор будет работать “вхолостую”, никакая полезная
работа не выполняется. Применение многопоточности решает эту
проблему. Если один поток находится в режиме ожидания, в другом могут
продолжаться полезные вычисления.
Параллельное программирование
Рассмотрим аппаратные решения для реализации параллельного программирования. Все существующие технологии можно условно разделить на две части: многопроцессорная обработка информации и эффективные способы распараллеливания в рамках одного процессора.
Рассмотрим классы многопроцессорных машин. Оценивать производительность будем по двум критериям: скорость выполнения независимого процесса (без учета межпроцессного обмена данными) и эффективность межпроцессных взаимодействий. Будем ставить условные отметки по 5-и бальной системе.
П - процессор, К - кэш (или несколько кэшей, последовательно соединенных), ОЗУ - оперативная память компьютера
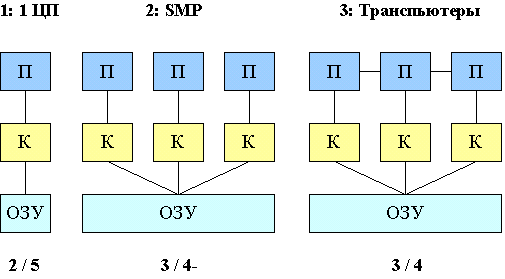
1. Обычная рабочая станция с одним центральным процессором. Одновременная работа нескольких процессов эмулируется, т.е. в один момент времени может выполняться только одна последовательность команд. Для смены контекста (переключения задач) приходится часто перемещать информацию между кэшами и ОЗУ. Скорость выполнения отдельного процесса минимальна. Обмены же можно осуществлять через кэш. Фактически может отсутствовать пересылка информации, ведь все запущенные программы работают с одним ЦП и кэшем.
2. Многопроцессорный компьютер с симметричным (т.е. равноправным)
доступом к памяти (SMP). Каждый процесс получает свой процессор и
кэш. (если процессов столько же сколько и процессоров). Узкое место –
общая шина для доступа к ОЗУ. Если процессоров слишком много, то
часто будут возникать конфликты и простои при одновременном доступе к
одной области ОЗУ. С другой стороны ОЗУ – медленное устройство.
Оно будет не справляться со слишком интенсивными операциями
чтения/записи. Поэтому такие машины делают с числом процессоров до 16
(32 – крайний случай).
3. Транспьютеры - специальные процессоры с портами прямой связи. В остальном тоже самое, что и SMP.
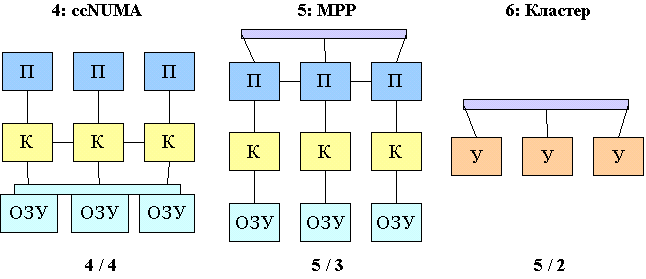
4. Компьютеры с неоднородным доступом к памяти (NUMA). ОЗУ физически разделено. Но логически - единое устройство, с единым адресным пространством. Если процессор обращается к "своему" участку памяти - скорость доступа максимальна. Иначе, несколько медленнее (но не намного, в некоторых машинах порядка 6 раз). Когда процессоры обращаются к разным физическим участкам, работают разные коммутаторы, разные шины, разные устройства ОЗУ. Одно из слабых мест SMP - межпроцессорный обмен требует передачи данных кэш1-ОЗУ-кэш2. Разработано аппаратное решение - технология когерентных кэшей. Такие машины (ccNUMA) делают с сотнями процессоров.
5. Компьютеры с массовым параллелизмом (MPP). Каждый процесс получает отдельный процессорный блок, со своей ОЗУ. Благодаря этому скорость выполнения независимого процесса максимальна. Межпроцессорные обмены производятся через специальную коммуникационную среду. Информация по ней передается на порядок(дки) медленее, чем через ОЗУ. Обмен по ком. среде производится последством механизма посылки сообщений. Один вычислительный узел посылает сообщение (запрос, содержащий различные данные) другому. Сообщение ассинхронно передается, пока не достигнет адресата. Для подтверждения получения информации посылается ответ - обратное сообщение. Такие машины можно строить с очень большим кол-вом процессоров.
6. Кластер, это MPP, где вместо процессорных блоков используются обычные рабочие станции (узлы сети). Вместо коммуникационных устройств - распространенные решения для локальных сетей. Межпроцессорный обмен в таких системах происходит медленнее всего. Но кол-во процессоров может быть огромно. Существуют кластеры с тысячами процессоров (и больше). Кластеры бывают неоднородными. Можно объединять самые разные компьютеры. Разной мощности, с разной ОС. Удобство кластеров для институтов и организаций в том, что он такая вычислительная машина может быть "бесплатной". Рабочие станции могут продолжать использоваться в штатном режиме. Время от времени можно запускать кластерное ПО и превращать сеть в мощный многопроцессорный аппарат.
На основе кластерных технологий создают метакомпьютеры. Это сильно распределенные и неоднородные кластеры. Коммуникационной средой является Интернет. Скорость передачи данных падает (и очень сильно), зато можно объединять огромное кол-во компьютеров для каких либо расчетов. ПО для метакомпьютеров должно учитывать одну особенность: любой узел может выключиться (или наоборот, подключиться к системе) в любой момент времени.
Существуют алгоритмы с очень интенсивным межпроцессорным обменом. Для таких программ лучше всего применять NUMA или SMP. Есть множество задач, где передача информации между процессорами умеренна. Тогда преимущество получают архитектуры MPP и кластеры.
Mozart поддерживает модель с распределенной памятью. Т.е. удобнее всего писать программы для кластеров (и MPP). Но и на SMP (и NUMA) такие программы будут работать довольно эффективно. Хотя преимущества SMP - общая физическая память использоваться не будет. (в следующей версии Mozart это положение может измениться. Возможно, будет добавлено автоматическое определение "смежных" процессов (т.е. выполняющихся на одной многопроцессорной рабочей станции). В таком случае обмен между процессами будет производиться через общую память.) Oz содержит средства посылки сообщений между процессами. Также виртуальная машина интерпретатора поддерживает логическую общую память. Переменные, процедуры и другие объекты, созданные на разных вычислительных узлах, "видны" в общем контексте выполнения. Т.е. программист может обращаться к различным объектам в программе, не зависимо от их физического расположения. Очень удобно, но этим механизмом нельзя злоупотреблять. Иначе легко получить очень медленную программу.
Ближе к делу
Заметим, что данная статья является ознакомительной. Программы не оптимизировались специально для достижения максимальной эффективности. В нашем случае важнее читабельность исходных текстов, простота реализации. Также не будет подробно объясняться синтаксис Oz и т.п.. Статья не претендует на полный обзор средств параллельного программирования в Mozart. Для подробного изучения этой системы программирования, лучше читать стандартную документацию и материалы, доступные в глобальной сети. Одна из лучших книг (ее легко найти в Интернете): "Concepts, Techniques, and Models of Computer Programming" Peter Van Roy, Seif Haridi. На сайте, посвященном Mozart (http://www.mozart-oz.org) действует список рассылки для пользователей. (там есть и наши соотечественники :-) )
Жизнь
Есть такой простейший клеточный автомат. Возьмите листок в клетку. Некоторые клетки пусты, другие же пометьте. Следующий кадр "эволюции" клеток строится по простому правилу:
-
если вокруг клетки больше 3х или меньше 2х соседей - она исчезает;
-
если вокруг пустой клетки ровно 3 соседа - появляется новая клетка.
Очень просто запрограммировать этот процесс и наблюдать за развитием клеточного мира. В программе создадим два массива: текущий кадр, и поле для построения следующего. Поле проходим во вложенных циклах по координатам X и Y.
Прoстейшая однопоточная версия в файле life.oz.
Попробуем запрограммировать алгоритм, используя легкие потоки (Л. потоки). Поле разобьем на маленькие квадраты. Каждый независимый поток обрабатывает свою область. Все потоки работают с общими массивами. В исходном тексте (файл lifep.oz) выделим алгоритм для параллельного выполнения в отдельную процедуру Task. Л-поток в Oz запускается конструкцией thread ... end. Все, что стоит внутри конструкции, выполняется в отдельной нити. Это очень удобно. Например:
это основной поток
thread
здесь выполняем действия, параллельно с основным потоком
end
thread
и еще один поток
thread
ничто не мешает делать thread вложенными :-)
end
end
Вот так :-)
Также создадим версию с настоящим физическим параллелизмом по модели с распределенной памятью (lifed.oz). Для этого применяется модуль Remote. Задача, передаваемая процессу, выделяется в отдельный модуль-функтор. Процессы выполняются ассинхронно, максимально независимо. Поэтому мы должны применять методы посылки сообщений для синхронизации и передачи запросов и данных.
Задачу разделим не на квадраты, а на полосы по оси X. Каждый процесс будет выполнять свою часть поля, причем данные будут хранится локально.
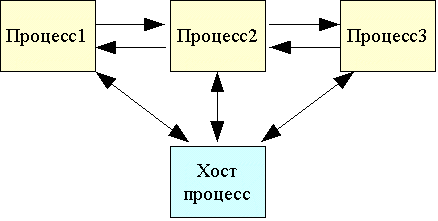
Стартовый (хост) процесс не выполняет вычисления для задачи. Он загружает задания в память других вычислительных узлов и координирует их работу. Результат считывается хост-процессом.
Вычислительные процессы связаны портами друг с другом для передачи необходимой информации.
Основной алгоритм:
-
Передать соседу слева первый столбец, соседу справа - последний. Синхронизация для того, чтобы убедится, что все данные переданы.
-
Собственно полезные вычисления.
-
Смена кадра. Синхронизация "барьер".
-
Повторить все с начала требуемое кол-во раз.
Рассмотрим подробнее некоторые приемы программирования, применяемые в Oz.
Некоторые приемы программирования
Программист, создающий программу, где различные действия производятся параллельно в разных процессах и потоках, сталкивается с проблемой готовности данных. Допустим, один процесс (Процесс1) присваивает переменной A значение 7, а другой процесс (Процесс2) использует значение переменной A для каких-либо вычислений. Если Процесс2 обратится к переменной A, когда Процесс1 еще не записал значение, произойдет логическая ошибка в программе. Такие ошибки могут привести к непредсказуемым последствиям. В одних трансляторах произойдет сбой при обращении к несуществующему объекту. В других программа будет выполняться, но Процесс2 считает "мусорное" или нулевое значение переменной. Чтобы решить эти проблемы, была разработана концепция dataflow. Виртуальная машина транстлятора следит за состоянием переменных и автоматически контроллирует выполнение процессов и потоков. Переменная (на самом деле это не переменные - они не изменяемы) в Oz может быть объявленной, без определенного значения - свободная переменная.
Например:
local A in
...
Мы объявили переменную A, но значение она еще не получила.
Затем, мы может связать имя A с любым объектом:
A = 7
Теперь A - символическая ссылка на числовой объект, значение 7. Механизм dataflow следит за тем, связана переменная или свободна.
local A in
thread
{Time.delay 5000}
A = 7
end
{Wait A}
В точке {Wait A} программа приостановится и будет ждать, пока переменная A не будет связана с конкретным значением. Dataflow может использоваться и более широко (и менее явно).
for Msg in S do
...
end
Поток считывает сообщения из S. Причем, если следующее сообщение еще не готово, поток будет автоматически приостановлен. Как только данные будут доступны, поток продолжит работу.
Вызов удаленной процедуры по технологии клиент-сервер
Сервер (процесс, который будет отрабатывать запросы) должен создать порт для передачи запросов. Порт (Port) - реализация механизма передачи сообщений в Oz.
P = {Port S}
Процедуры в Oz записываются в фигурных скобках. Мы создали порт P, привязанный к потоку данных S. S - фактически очередь сообщений. Сервер должен считывать сообщения из S и отрабатывать их. Клиент использует переменную P для посылки сообщений.
{Send P 'Hello!'}
Мы послали сообщение в порт P, содержащий атом 'Hello!'. (Атом это неделимая конструкция языка).
Клиент и сервер могут работать независимо в разных процессах (и на разных компьютерах), поэтому сервер должен быть готов принять сообщение в любой момент времени.
thread
for Msg in S do
отрабатываем запрос, содержащийся в сообщении Msg
end
end
Но этого не достаточно. Как клиент узнает, что сообщение отработано? Применим следующую модель: процедура - имя процедуры, входные параметры, выходные параметры, флаг синхронизации. Здесь активно используется технология dataflow.
Сервер:
thread
for Msg in S do
case Msg
of procedure1(Par Ans R) then
Par - входные параметры
Ans - выходные, мы должны присвоить им нужное значение
R = true % в конце вычислений устанавливаем флаг сихронизации,
% клиет узнает что выполнение процедуры закончено
[] procedure2(... и т.д.
...
end
end
end
Клиент:
{Send P procedure1(Par Ans R)}
{Wait R}
Это один из часто используемых механизмов синхронизации процессов. Несколько процессов выполняют одну и ту же программу над различными наборами данных. В определенные моменты они должны синхронизироваться. На "барьере" каждый процесс приостанавливается. Программа продолжит работать, только когда все процессы дойдут до барьера.
Сервер, реализующий механизм "барьер":
Pinbarrier Sinbarrier
Pinbarrier = {NewPort Sinbarrier}
thread
local N ArB in
N = {NewCell 1}
ArB = {Array.new 1 NumProc nil} % массив хранит переменные
% синхронизации dataflow для каждого процесса.
for Msg in Sinbarrier do
case Msg
of barrier(B) then {Array.put ArB @N B}
end
N := @N + 1
if @N > NumProc then % если пришло кол-во сигналов "барьер"
% соответствующее кол-ву процессов, значит все дошли.
for I in 1..NumProc do
{Array.get ArB I} = true % устанавливаем флаги для всех процессов
end
N := 1
end
end
end
end
На стороне клиента:
proc {Barrier}
local B in
{Send Pbarrier barrier(B)} % сигнал "барьер" серверу синхронизации
{Wait B} % ждем установления флага синхронизации
end
end
В нужном месте программы производится вызов {Barrier}.
Тесты
Программы были запущены в режиме 40х40 клеток, 100х100 клеток. Также 200х200 без отображения результатов на экране. Во всех случаях вычисляется 1000 кадров. Версия на легких потоках создает отдельную нить для каждого квадратного участка поля 5х5. Т.е. задача 40х40 порождает 64 потока, 100х100 - 400, 200х200 - 1600 потоков.
Используемое оборудование:
а) Кластер:
Хост машина: Celeron 800 МГц 256 Мб ОЗУ - в расчетах не участвует
1. 10.254.0.10 Pentium 4 2.8 ГГц 256 Мб ОЗУ
2. 10.254.0.14 Pentium 4 3 ГГц 512 Мб ОЗУ
3. 10.254.0.15 Pentium 4 1.9 ГГц 1024 Мб ОЗУ (быстрая память RIMM)
Комуникационная среда: Fast Etherten, машины объединены через концентратор.
б) Локальные запуски однопроцессорных программ - машина № 2.
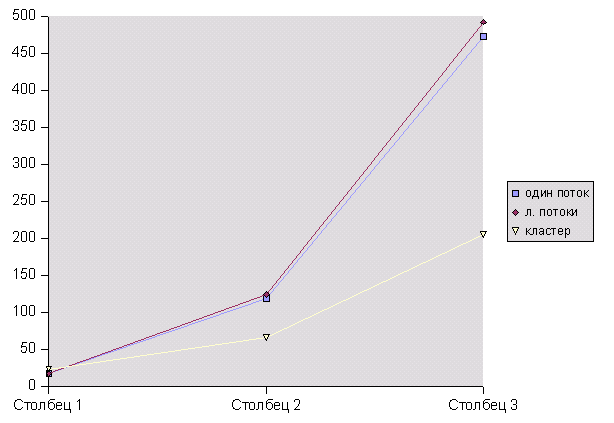
Результаты:
|
программа
|
объем
|
время
|
|
один поток
|
40
|
17
|
|
л. потоки
|
40
|
17
|
|
кластер
|
40
|
23
|
|
один поток
|
100
|
118
|
|
л. потоки
|
100
|
124
|
|
кластер
|
100
|
66
|
|
один поток
|
200
|
472
|
|
л. потоки
|
200
|
492
|
|
кластер
|
200
|
205
|
|
один поток
|
17
|
118
|
472
|
|
л. потоки
|
17
|
124
|
492
|
|
кластер
|
23
|
66
|
205
|
Серия 1:
Л. потоки не отличаются от однопоточной версии.
Кластер менее эффективен на маленьких объемах вычислений.
Серия 2:
Накладные расходы л. потоков: 5%
Эффективность кластера: 1.8
Серия 3:
Накладные расходы л. потоков: 4%
Эффективность кластера: 2.3
Выводы:
-
Накладные расходы на л. потоки ~4%. В Серии 1 разница незаметна из-за округления результатов до целых. Величина расходов достаточно мала. Следовательно, не имеет смысла специально придерживаться однопоточной техники программирования.
-
Кластер эффективен при достаточно больших объемах вычислений на каждом процессоре. При этом доля затрат на межпроцессорные взаимодействия должна уменьшаться. Важно задействовать эффективное кол-во процессоров (закон Амдала). Для этого необходимы пробные запуски и оптимизация алгоритма. Немаловажно правильно распределить нагрузку на каждый процессор (в случае неоднородной вычислительной сети).
Обратите внимание, что объем параллельной (и особенно распределенной) программы и ее сложность заметно увеличивается. Поэтому следует четко представлять "стоит ли овчинка выделки". Параллельное программирование следует применять либо когда алгоритм становится проще и естественнее в параллельной реализации, либо если требуется задействовать значительную вычислительную мощность для более быстрого получения результатов.
|