[
Содержание
| 1
| 2
| 3
| 4
| 5
| 5.1
| 5.2
| 5.3
| 5.4
| 5.5
| 5.6
| 5.7
| 5.8
| 5.9
| 6
| 6.1
| 6.2
| 6.3
| 6.4
| 6.5
| 7
| 7.1
| Литература
]
© 2003 И.А. Дехтяренко
5.2. Рекурсия.
|
И обнаружил микроскоп
Что на клопе бывает клоп,
Питающийся паразитом.
На нём - другой, ad infinitum.
Джонатан Свифт |
Рекурсивные определения.
Обычный способ решения задачи - разбиение её на
более простые подзадачи, решение этих подзадач и
объединение полученных решений. В простейшем
случае мы просто объединяем некоторое
количество других (например, стандартных)
функций с помощью комбинационных форм.
(define (zero? x )
(= x 0))
(define (tan x)
(/ (sin x) (cos x)))
(define (average x y)
(/ (+ x y) 2))
В тех случаях, когда область определения
функции разбивается на подобласти, определяемые
некоторыми условиями, мы применяем условные
выражения.
(define (min x y)
(if (< x y) x y))
(define (abs x)
(if (< x 0) (- x) x))
(define (sign x)
(cond ((> x 0) 1)
((= x 0) 0)
((< x 0) -1))))
Иногда более простая подзадача оказывается
аналогичной исходной. В этом случае, определяя
функцию, мы будем вынуждены сослаться на неё же.
Такие определения называются рекурсивными.
Способность определять функции рекурсивно -
важная особенность функционального
программирования. Это - единственный общий
механизм определения нетривиальных функций,
выполнения чего-нибудь сопоставимого с
итерацией.
Простейшее рекурсивное определение:
(define (ad-infinitum) (ad-infinitum))
Попытка вычислить значение этой «функции»
приведёт к бесконечному процессу. Для того чтобы
рекурсивное определение было полезным
необходимо выполнение следующих двух условий:
- Наличие нерекурсивного определения для
базового случая.
- Параметр рекурсивного обращения должен быть
«проще», чем параметр определяемой функции.
Канонические примеры, без которых не обходятся
ни в одном рассказе о рекурсии - определения
факториала и последовательности чисел
Фибоначчи.
Факториал положительного целого числа n
определяется как произведение всех чисел от 1 до
n.
n!=1*2*3*…*n.
Имеется множество способов вычислять
факториал. Один из них состоит в том, чтобы
использовать очевидное свойство: для любого n>1
n! = n*(n-1)!. Таким образом, мы можем вычислить n!,
вычисляя (n - 1)! и умножая результат на n. Если мы
прибавим соглашение что 1! = 1, получим следующее
определение:
(define (fac n)
(cond ((= n 1) 1)
((> n 1) (* n (fac (- n 1))))))
(fac 20)
2432902008176640000
(/ (fac 100) (fac 99))
100
Определение чисел Фибоначчи само по себе
рекурсивно. Каждое число в последовательности,
кроме двух первых является суммой двух
предшествующих.
F1 = 1
F2 = 1
Fn = Fn-1+ Fn-2.
Это определение непосредственно записывается
на Лиспе.
(define (fib n)
(cond ((= n 1) 1)
((= n 2) 1)
((> n 2) (+ (fib (- n 1)) (fib (- n 2))))))
Ещё один пример - формула для вычисления
биномиальных коэффициентов по схеме
треугольника Паскаля.
C(0, n) = C(n, n) = 1
C(m, n) = C(m, n-1) + C(m-1, n-1)
Снова, мы просто переписываем математическое
определение на Лиспе.
(define (C m n)
(cond ((= m 0) 1)
((= m n) 1)
(else (+ (C m (- n 1))
(C (-m 1) (- n 1))))))
Наибольший общий делитель
Наибольший общий делитель (НОД) двух
натуральных чисел a и b определен, как наибольшее
натуральное число, которое делит a и b без остатка.
Мы могли бы попытаться буквально следовать этому
определению: найти все делители чисел а и b, затем
выбрать из них общие делители, и, наконец, найти
среди них наибольший. Однако очевидная сложность
этого процесса может побудить нас потратить
некоторое время на анализ проблемы и попытаться
разработать «теорию НОД». Например, мы могли бы
обнаружить, что если число n делит оба числа а и b,
то оно делит их сумму и разность, и заключить
отсюда, что
НОД(a, b) = НОД(a+b, b) = НОД(a, a+b) = НОД(a-b, b) = НОД(a, a-b).
Можно найти ещё множество интересных свойств
НОД, но уже здесь мы замечаем, что НОД(a-b, b)
выглядит несколько «проще» чем НОД(a, b) в том
смысле, что приходится иметь дело с меньшими
числами. Добавляя сюда тот очевидный факт, что
НОД(a, a) = a, приходим к знаменитому алгоритму
Евклида.
(define (gcd a b)
(cond ((= a b) a)
((> a b) (gcd (- a b) b) )
((< a b) (gcd (- b a) a) )))
- Упражнение
- Определите функцию возведения числа в целую
степень.
- Упражнение
- Усовершенствуйте функцию
gcd, используя
другие свойства НОД.
Итерационные и рекурсивные процессы.
Рассмотрим теперь, как вычисляются некоторые
из определенных нами функций. Мы опустим
промежуточные шаги, сосредоточившись на
рекурсивных вызовах.
(gcd 27 12)
(gcd 15 12)
(gcd 3 12)
(gcd 3 9)
(gcd 3 6)
(gcd 3 3)
3
(fac 5)
(* 5 (fac 4)))
(* 5 (* 4 (fac 3)))
(* 5 (* 4 (*3 (fac 2))))
(* 5 (* 4 (*3 (* 2 (fac 1)))))
(* 5 (* 4 (*3 (* 2 1))))
120
(fib 5)
(+ (fib 4) (fib 3))
(+ (+ (fib 3) (fib 2)) (fib 3))
(+ (+ (+ (fib 2) (fib 1)) (fib 2)) (fib 3))
(+ (+ (+ 1 (fib 1)) (fib 2)) (fib 3))
(+ (+ (+ 1 1) (fib 2)) (fib 3))
(+ (+ 2 (fib 2)) (fib 3))
(+ (+ 2 1) (fib 3))
(+ 3 (fib 3))
(+ 3 (+ (fib 2) (fib 1)))
(+ 3 (+ 1 (fib 1)))
(+ 3 (+ 1 1))
5
Первый процесс развивается линейно. Его
состояние на каждом шаге, определяется
значениями аргументов функции gcd. Такие
процессы, состояние которых может быть полностью
описано конечным числом переменных, называют итерационными.
Второй процесс - пример рекурсивного процесса.
Его развитие сопровождается расширением и
сокращением вычисляемого выражения. Расширение
происходит, когда процесс создает цепочку
задержанных операций, а сокращение - когда эти
операции выполняются. Таким образом, описание
состояния этого процесса требует учета тех
операций, которые будут выполнены позже.
Следовательно, интерпретатор должен кроме
значений аргументов хранить дополнительную
информацию, объем которой пропорционален
количеству задержанных операций. При вычислении (fac
n), длина цепочки задержанных операций растет
линейно от n, точно так же, как число шагов. Такой
процесс называется линейно рекурсивным
процессом.
Третий пример демонстрирует то, что называется древесной
рекурсией. Чтобы вычислить (fib 5), мы
должны вычислить (fib 4) и (fib 3).
Далее, чтобы вычислить (fib 4), мы
вычисляем (fib 3) и (fib 2).
Развитие процесса напоминает обход дерева. На
каждом уровне каждая ветвь разделяется на две,
потому что fib вызывает себя дважды при
каждом вызове.
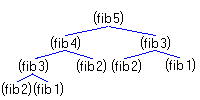
Обратите внимание, что многие вычисления
повторяются. Нетрудно показать, что число
листьев в дереве вычисления Fn в точности
равно Fn. Таким образом, число шагов
выполняемых процессом, растет по экспоненте. С
другой стороны, требования к памяти растут
только линейно, потому что мы должны сохранить
только путь от вершины дерева до текущей точки
процесса. Вообще, число шагов, требуемых
древесно-рекурсивным процессом пропорционально
числу узлов в дереве, в то время как требуемое
пространство пропорционально максимальной
глубине дерева.
- Упражнение
- Докажите то, что «нетрудно показать».
- Упражнение
- Оцените требования
fib к памяти для
реализации, использующей нормальный порядок
редукции.
Не следует путать понятие рекурсивного
процесса с понятием рекурсивно определенной
функции. Когда мы говорим, что функция определена
рекурсивно, мы подразумеваем чисто
синтаксический факт, что определение функции
обращается (непосредственно или косвенно) к этой
же функции. Когда же мы описываем процесс, как
рекурсивный, мы говорим о том, как этот процесс
развивается. Большинство обычных языков (таких
как Паскаль и Си) реализовано таким образом, что
исполнение любой рекурсивной процедуры требует
объема памяти, который растет с числом вызовов
процедуры, даже когда описанный процесс, в
принципе, итерационный. Итерационные процессы в
таких языках могут быть описаны только с помощью
специальных конструкций цикла типа while
или for. Для функциональных языков это не
так. Итерационный процесс будет выполняться с
использованием постоянного объема памяти, даже
если он описан рекурсивной функцией. Конечно,
императивные языки тоже можно реализовывать
таким образом, но для них это несколько сложнее и
к тому же не так актуально.
Рекурсивное описание итерационного процесса
часто называют хвостовой рекурсией. Общий вид
такого определения:
(define (f args…)
[cond (c1 t1)
...
(cm tm)
(r1 (f s1))
...
(rn (f sn))])
Здесь ti и si - «простые» выражения, не
содержащие рекурсивных вызовов.
Поскольку итерационные процессы обладают
привлекательными вычислительными свойствами,
часто стараются дать определение функции именно
в такой форме. Например, можно сформулировать
итерационный процесс для вычисления факториала.
Для этого мы применим трюк, известный как «метод
накапливающего параметра». Определим
вспомогательную функцию facit(n,s) = n!*s.
Очевидно, что
facit(1, s) = s
facit(n, s) = n!*s = (n-1)!*n*s = facit(n-1, n*s)
n! = facit(n, 1)
Эти уравнения уже можно записать на Лиспе.
(define (fac-iter n s)
(if (= n 1)
s
(fac-iter (- n 1) (* n s))))
(define (fac n) (fac-iter n 1))
Можно описать итерационный процесс и для
вычисления чисел Фибоначчи. Идея состоит в том,
чтобы одновременно преобразовывать к пару целых
чисел (Fk-1, Fk), отображая её в (Fk, Fk+1).
Применив n-1 раз это преобразование к паре чисел
(1, 1), то есть к (F1, F2) мы получим
пару (Fn, Fn+1).
(define (fib-iter a b count)
(if (= count 0)
a
(fib-iter b (+ a b) (- count 1))))
(define (fib n)
(fib-iter 1 1 (- n 1)))
Новая «усовершенствованная» процедура fib
вычисляет ту же самую функцию, что и
первоначальная, то есть возвращают те же
значения для тех же аргументов. Однако, разница в
числе шагов, выполняемых этими процедурами,
огромна. Для первой оно растёт как экспонента, а
для второй - линейно.
Из сказанного не стоит делать вывод, что
рекурсивные процессы бесполезны. Во-первых,
древесная рекурсия - естественный и мощный
инструмент для обработки иерархически
структурированных данных. Во-вторых, даже в
простых случаях рекурсивные процессы могут быть
полезны для того, чтобы понять проблему и
спроектировать программу. Например, хотя первая
процедура fib намного менее эффективна, чем
вторая, она - всего лишь прямая трансляция на Лисп
определения последовательности Фибоначчи.
Создание же итерационного алгоритма потребовало
определённой изобретательности1.
Поэтому, интерес представляют методы
автоматического преобразования процедур,
определяющих рекурсивные процессы, в
эквивалентные им процедуры, определяющие
итерационные процессы. Однако, это нелёгкая и в
общем случае невыполнимая задача.
- Упражнение
- «Функция Аккермана» определяется следующими
уравнениями:
ack(0,n) = 1 + n;
ack(m,0) = ack(m-1, 1);
ack(m,n) = ack(m-1, ack(m, n-1)).
1. Запишите это определение на Лиспе.
2. Попытайтесь создать итерационный алгоритм
вычисления этой функции и запишите его на
любимом языке программирования. Ваша программа
должна использовать только конечное число
переменных и не должна реализовывать рекурсию,
например, с использованием стека.
В случае удачного решения обязательно
опубликуйте результат!
- Упражнение
- Подумайте о возможности общего метода,
позволяющего ускорить выполнение процедур типа
fib,
C и ack, не изменяя их определений.
Пример: извлечение квадратного корня
|
В качестве примера
хорошего процедурного стиля можно привести
функцию извлечения квадратного корня.
Бьярне Страуструп |
Пусть перед нами стоит задача написать функцию,
вычисляющую квадратный корень заданного числа.
Мы можем начать с её спецификации
sqrt(a) = x, где x>=0 и x2 = a.
Впрочем, такая спецификация чересчур
оптимистична. Вообще, работа с вещественными
числами таит немало опасностей, таких как
«переполнения», «машинные нули» и т.п. Поэтому
будем осторожны и ограничимся утверждением, что
значение x «достаточно близко» к квадратному
корню из a, не уточняя пока, что мы под этим
подразумеваем.
Но что делать дальше?. Как вообще вычисляют
квадратные корни? Один из методов был описан
Героном Александрийским в первом веке нашей эры2. Возьмём произвольное число
x в качестве приближенного значения для
квадратного корня из a. Тогда x * a/x = a,
причём одно из значений x и a/x заведомо меньше
искомого корня, а другое - больше. Значит, их
среднее арифметическое будет ближе к корню, и
можно определить «улучшающую функцию» improve.
(define (improve x a)
(average x (/ a x)))
Последовательно применяя эту функцию мы будем
получать всё лучшие и лучшие приближения к
фактическому квадратному корню, пока не получим
приемлемое для наших целей приближение. Таким
образом, мы можем описать итерационный процесс.
(define (sqrt-iter x a)
(if (acceptable? x a)
x
(sqrt-iter (improve x a) a)))
Теперь уже необходимо определить, что мы
подразумеваем под «приемлемым приближением».
Например, мы можем улучшать ответ, пока его
квадрат не будет отличаться от подкоренного
выражения меньше чем на определенный допуск.
(define (acceptable? x)
(< (abs (- (sqr x) a)) 0.00001))
Наконец, нам требуется способ выбора
начального приближения. Например, мы можем
предположить, что квадратный корень любого числа
равен 1. Собирая все вместе, получаем.
(define (sqrt a)
(sqrt-iter 1.0 a))
(define (sqrt-iter x a)
(if (acceptable? x a)
x
(sqrt-iter (improve x a) a)))
(define (improve x a)
(average x (/ a x)) )
(define (acceptable? x)
(< (abs (- (sqr x) a)) 0.00001))
Обратите внимание, что пользователю,
вздумавшему вычислить квадратный корень,
абсолютно безразлично как будет реализована эта
процедура, точно так же, как и нас совершенно не
волновало, каким образом определены функции sqr,
abs и т.п. Единственное, что для него важно,
чтобы процедура соответствовала своей
спецификации, чтобы она вычисляла квадратный
корень. Таким образом, процедура выступает в
качестве своего рода «черного ящика»,
отображающего число в его квадратный корень, и
математическое понятие «функции квадратного
корня» как нельзя лучше соответствует этой
концепции.
Небольшая проблема состоит в том, что
единственная функция, представляющая интерес
для пользователя - собственно sqrt, а другие
функции могут только его запутать. Хуже того, он
не сможет определить свою функцию под названием improve
или acceptable?, потому что sqrt уже
использует эти имена. Эта проблема становится
серьезной при создании больших систем многими
программистами. Например, при построении большой
библиотеки вычислительной математики, многие
функции вычислялись бы как последовательные
приближения и, таким образом, могли бы иметь
множество вспомогательных функций с именами
типа improve. Чтобы ограничить область
видимости таких вспомогательных функций,
используются локальные определения, аналогичные
определению вложенных процедур на Паскале.
Например, нашу процедуру мы могли бы записать в
виде:
(define (sqrt a)
(define (acceptable? x a)
(< (abs (- (sqr x) a)) 0.00001))
(define (improve x a)
(average x (/ a x)) )
(define (sqrt-iter x a)
(if (acceptable? x a)
x
(sqrt-iter (improve x a) a)))
(sqrt-iter 1.0 a))
Теперь acceptable?, sqrt-iter, improve
видимы только внутри определения sqrt.
Такие вложенные определения придают программам
блочную структуру подобную структуре программ
на Паскале3. Это важный
инструмент для структурирования больших
программ, особенно если учесть, отсутствие
других средств для этого. Но блочная структура
предоставляет и дополнительные удобства. Так как
аргумент a находится в той же области
видимости, что и вспомогательные функции, нет
необходимости передавать его явно, и мы можем
несколько упростить наши определения.
(define (sqrt a)
(define (acceptable? x)
(< (abs (- (sqr x) a)) 0.00001))
(define (improve x)
(average x (/ a x)) )
(define (sqrt-iter x)
(if (acceptable? x)
x
(sqrt-iter (improve x a) a)))
(sqrt-iter 1.0 a))
Конечно, блочная структура не решает всех
проблем и отсутствие модулей - серьезный
недостаток, который пытаются преодолеть4.
На самом деле наше определение «приемлемого
приближения» неудачно (подумайте почему).
Гораздо лучший результат даёт другой критерий:
вычисления прекращаются как только два
последовательных приближения отличаются меньше
чем на заданный допуск. Несложно изменить
программу так, чтобы она использовала этот
критерий.
(define (sqrt a)
(define (improve x)
(average x (/ a x)) )
(define (sqrt-iter x)
(let ((y (improve x)))
(if (near? y x)
y
(sqrt-iter y))))
(sqrt-iter 1.0))
(define err 0.000001)
(define (near? x1 x2)
(< (abs (- x1 x2)) err))
- Упражнение
- Найдите недостатки нового критерия и исправьте
их.
(Достаточно изменить процедуру near?).
- Упражнение
- Другой способ вычислить квадратный корень -
воспользоваться широко известным методом
деления отрезка пополам. Реализуйте этот метод.
1 Очень хороший пример
описывал Энтони Хоар. Придумав новый алгоритм
сортировки, он испытывал значительные трудности,
пытаясь объяснить другим его работу. Но,
познакомившись с Алголом-60 он смог элегантно
выразить его с помощью рекурсивной процедуры и
на свет появилась знаменитая QUICKSORТ.
2 В действительности этот
метод гораздо старше. Он был известен ещё древним
вавилонянам.
3 Возможно, точнее было бы
сравнить её со структурой программ на Алголе.
Этот язык оказал значительное влияние на авторов
Scheme. Вообще, «три источника» Scheme - ранние версии
Лиспа, Алгол-60 и «теория акторов» Карла Хьюита.
4 Многие реализации Scheme
предоставляют различные средства для
организации «модулей» или «пакетов», но
отсутствие общего стандарта делает программы,
написанные с их использованием, непереносимыми.
[
Содержание
| 1
| 2
| 3
| 4
| 5
| 5.1
| 5.2
| 5.3
| 5.4
| 5.5
| 5.6
| 5.7
| 5.8
| 5.9
| 6
| 6.1
| 6.2
| 6.3
| 6.4
| 6.5
| 7
| 7.1
| Литература
]
|