[
содержание
| предыдущая тема
| следующая тема
]
Содержание темы
Назначение семантического
анализа. Семантическая модель программы.
Построение элементов таблицы имен.
Синтаксически управляемый перевод.
Использование синтаксически управляемого
перевода при построении таблиц имен.
Использование синтаксически управляемого
перевода при работе с таблицей имен.
Назначение семантического анализа
Синтаксический
разбор определяет принадлежность
входной цепочки заданному языку. Однако
одного разбора недостаточно для генерации
кода или его интерпретации. Необходим
дополнительный набор действий, которые:
определяют
смысловую нагрузку объектов анализируемой
программы;
порождают из
синтаксического представления программы
(в виде цепочки символов) ее семантическую
(смысловую) модель;
анализируют
корректность использования элементов
построенной семантической модели перед
построением выходного представления
(кода объектной машины).
Эти
действия определяются как семантический
анализ, заключающийся в формировании
семантической модели программы. Его
тоже можно разбить на отдельные фазы и
организовать их выполнение за один или
несколько проходов:
Построение
и использование таблицы имен.
Построение
операторной модели.
Контекстный
анализ элементов семантической модели.
Семантическая модель программы
Семантическая модель
определяет назначение, структуру, методы
использования и принципы функционирования
программных объектов. Она предоставляется
пользователю через семантику, всегда
задаваемую при описании языка
программирования, и определяет поведение
виртуальной машины, непосредственно
выполняющей программы, написанные на
этом языке. Такая невидимая вычислительная
машина присуща любому языку программирования.
Мы используем ее для мысленной прокрутки
написанных программ, руководствуясь
при их «виртуальном выполнении» заданной
семантикой отдельных операторов и
обрабатываемых ими данных.
Семантическая модель
программы может даже существовать в
отрыве от синтаксиса языка, например,
в виде структур данных, размещенных в
памяти компьютера или таблицах баз
данных. По этим структурам можно
восстановить текст исходной программы,
использовать для иного способа описания
(например, графический), или порождать
тексты программ с использованием других
синтаксических правил (при сохранении
исходной семантики). Это позволяет
говорить о том, что семантическая модель
является относительно независимым
компонентом, формируемым в результате
синтаксического анализа. Ее можно
считать также программой, освобожденной
от исходной синтаксической оболочки.
Существуют
различные трактовки структуры
семантической модели. Во многом они
связаны со степенью привязки к методу
описания синтаксиса языков программирования.
В частности, можно выделить следующие
варианты построения семантической
модели.
Построение
дерева разбора.
Построение
объектной модели.
Построение дерева разбора
В этом случае
семантическая модель программы является
отображением дерева разбора, выстраиваемого
в результате синтаксического анализа
программы. То есть, каждому правилу
грамматики соответствует эквивалентная
семантическая структура, которая
содержит вложенные структуры,
соответствующие нетерминалам в его
правой части и т.д. Дополнительные
объекты, используемые для представления
семантики языка, размещаются в этих
объектах-правилах.
Достоинством такого
подхода является его простота и
наглядность, связанная с однозначным
соответствием между синтаксическими
правилами и основными семантическими
структурами. Используя существующий
синтаксис можно достаточно быстро и
просто сформировать базовый набор
программных объектов, определяющих
семантику. Подобный подход широко
используется при построении трансляторов.
Вместе с тем, следует
отметить и ряд недостатков. Во-первых,
жесткая привязка к конкретному синтаксису
не позволяет иметь универсальное
представление семантических моделей
программы для различных трансляторов
с одного и того же языка, построенных с
использованием разных грамматик. Это
не позволяет использовать семантическую
модель как универсальный метод для
промежуточного представления программы.
Во-вторых, не все
метаязыки позволяют порождать
иерархическое дерево разбора. Например,
использование диаграмм Вирта и РБНФ
ведет к тому, что в его узлах используются
также списки объектов, выстраиваемые
по итеративным фрагментам правил. То
есть, в этом случае вряд ли уже имеет
смысл говорить о деревьях. Целесообразнее
манипулировать понятием «иерархический
список».
Построение объектной модели
Объектная модель
программы позволяет избавиться от ряда
недостатков, присущих дереву разбора.
В частности, она является универсальным
отображением семантики, не зависящим
от синтаксической структуры правил.
Это связано с тем, что объектная модель
ориентирована на непосредственное
представление структуры программных
объектов. Ее разработка вообще может
не учитывать синтаксис.
Являясь обобщенным
методом определения семантики, объектная
модель может использоваться не только
для генерации объектного кода. Она
обеспечивает формирование разнообразных
выходных представлений, удобных для
восприятия программистом. Например,
можно создавать диаграммы тех или иных
программных объектов, отображать, с
помощью специальных инструментов
иерархию и ассоциативные связи. Подобные
методы дополнительного восприятия
программ широко начинают использоваться
в современных инструментальных средствах
разработки.
К недостаткам подхода
следует отнести усложнение процесса
порождения объектной модели программы,
что обуславливается отсутствием
однозначного соответствия между
семантической моделью и синтаксическими
правилами. Однако, использование более
мощных метаязыков, например, диаграмм
Вирта, позволяет приблизить синтаксическое
описание к семантической структуре и
тем самым облегчить процесс построения.
Связь между построением семантической модели программы и генерацией кода
Семантическая модель,
являясь самодостаточным методом описания
программы, может быть построена полностью
за отдельный проход транслятора. В
дальнейшем ее можно сохранить на внешнем
носителе и использовать для различных
целей, включая и генерацию кода. Генерация
кода в этом случае может также производиться
в отдельном проходе по существующей
семантической модели.
Вместе с тем, в ряде
случаев, существование программы в виде
отдельной семантической модели не
является обязательным. Достаточно
бывает иметь только ее отдельный
фрагмент, необходимый, чтобы сформировать
часть кода объектной машины. После этого
данные, не нужные для дальнейшего анализа
можно уничтожить. Таким образом, генерация
кода может сочетаться с построением
отдельных фрагментов семантической
модели программы. Этот подход также не
отрицает построения полной семантической
модели и объектного кода одновременно.
Построение элементов таблицы имен
Создание и использование
имен (идентификаторов) – неотъемлемая
часть написания программы на любом
языке программирования. Транслятор
должен запоминать вводимые пользователем
имена, определять конфликты, связанные
с использованием объектов, обозначенных
именами, запрещать повторное определение
имен в пределах единой области их
существования. При этом учитывается и
то, что в некоторых языках программирования
допустимо использование одного и того
же имени в различных контекстах в рамках
единой области действия. Например, в
языках программирования C
и C++ допускаются одинаковые
имена меток, переменных, а также некоторых
других конструкций, имеющих различное
назначение. Кроме этого в C++
допускается перегрузка имен функций
[Страуструп99].
Разработка абстрактных описаний элементов таблицы имен
Имена группируются в таблице
имен. Каждое имя связанно с некоторым
объектом. Таких объектов в программе
может быть множество: метка, переменная,
элемент перечислимого типа, процедура,
функция, класс и т.д. Каждое из назначений
имеет свою структуру, определяющую
внутренние параметры объекта, а также
допускает использование в определенных
операциях. Существуют различные методы
и модели обобщенного представления
программных объектов, применяемые в
технологии программирования. В частности,
можно отметить методику Джексона
[Зиглер], диаграммы классов [Буч98]. Однако,
для описания структуры различных
объектов можно использовать и диаграммы
Вирта. При этом следует подчеркнуть,
что их использование в данном контексте
никоим образом не связано с порождением
и распознаванием цепочек. В данном
случае - это просто достаточно удобный
метод для абстрактного представления
структур данных, независимый от языка
программирования. Описание структур
данных, определяющих назначение основных
программных объектов, представлено на
рис. 11.1 - 11.10. При этом альтернативы
диаграмм Вирта используются для
представления различных объектов,
последовательности - для описания
составных структур данных, а циклы
определяют наличие контейнеров. При
этом особенности реализации контейнеров
оставляются на дальнейшее усмотрение.
На рис.11.1 представлено описание
назначения имени. Из него следует, что
имя может определять следующие программные
объекты: или тип, или переменную, или
метку, или процедуру. В реальных языках
программирования возможны и другие
варианты имени, которые здесь, из-за
упрощения, не рассматриваются. Каждое
из представленных назначений имен
может, в свою очередь тоже являться
составной конструкцией, что и определяется
на следующих рисунках.
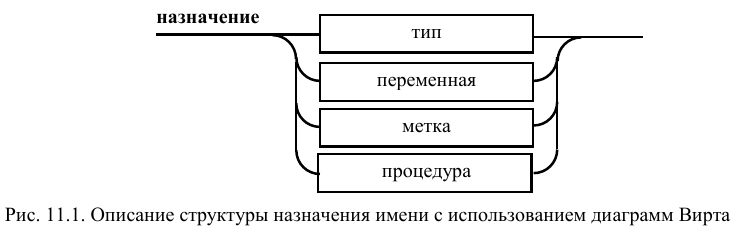
На рис. 11.2 представлена структура типа.
Он содержит элемент, задающий общий
размер типа и набор альтернатив,
представляющих различные варианты:
скаляр, вектор, структуру, объединение.
Каждый из этих вариантов имеет свою
организацию.
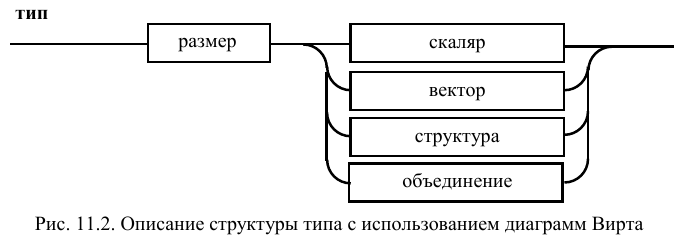
На рис. 11.3 показана структура скаляра.
Он задается одной из альтернатив,
соответствующей предопределенному
типу: целому, действительному, символьному.
Здесь также, из всего многообразия
базовых типов, оставлены для иллюстрации
только три основных.
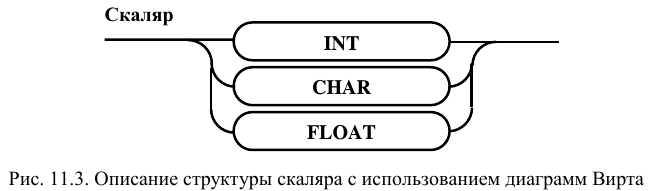
Рис. 11.4 показывает структуру
векторного типа. Он состоит из элемента,
задающего длину вектора (задается целым
числом), и элемента, определяющего единый
тип для всех его элементов. Следует
отметить, что рекурсивное определение
типа позволяет в данном случае формировать
векторы, состоящие из объектов любого
типа . Можно задавать вектор векторов,
что позволяет строить матрицы, вектор
структур и т.д.

Организация структурного
типа приведена на рис. 11.5. Он состоит из списка элементов
структуры, который может быть и пустым.
Пустая структура позволяет вводить в
программу необходимые конструкции и
обеспечивать их корректную трансляцию
еще до того момента, как будет окончательно
определена их внутренняя организация.
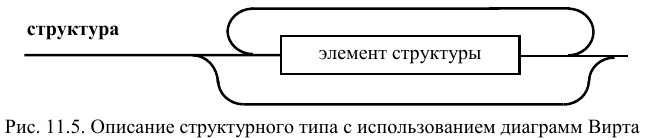
Аналогичным образом определяется и
объединение, показанное на рис. 11.6. Отличие заключается в том,
что список, возможно пустой, состоит из
элементов объединения, отличающихся
по строению от элементов структуры.
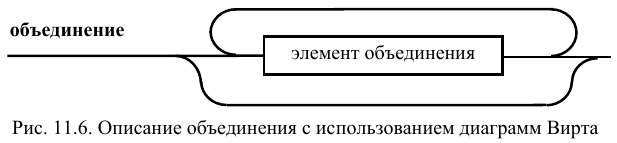
Элемент структуры (рис. 11.7) содержит тип и параметр,
определяющий смещение элемента
относительно начала структуры. Это
смещение определяет последовательность
размещение элементов структуры в памяти.
В принципе, оно может специально не
храниться, а вычисляться каждый раз при
обработке структуры. Однако, хранение
данного параметра вместе с элементом
позволяет провести необходимые вычисления
только один раз при формировании
структурного типа, а в дальнейшем только
использовать полученное значение.

Все элементы объединения
располагаются без смещения. Поэтому,
элемент объединения содержит только
конструкцию, определяющую его тип (рис. 11.8).

Специфической особенностью
переменной является то, что она имеет
тип, а также размещается в памяти
компьютера. При этом размещение может
происходить в различных по назначению
областях памяти. Например, известны
такие виды областей памяти, как
регистровая, глобальная, локальная и
т.д. Кроме того, переменная размещается
в указанном виде памяти, начиная с
определенного адреса. Поэтому структура
переменной содержит три основных
параметра: тип, вид области памяти и
адрес начала размещения (рис. 11.9).

Параметром метки может служить
определитель ее местоположения в
программе (рис. 11.10). В общем случае его конкретная
реализация сильно зависит от представления
программного кода. Он может быть
указателем на промежуточную команду,
адресом команды в объектном или абсолютном
коде. Определитель местоположения может
также быть командой-меткой, непосредственно
вставляемой в промежуточное представление
программы, что облегчает в дальнейшем
использование меток и генерацию
объектного кода. Данный вариант будет
обсуждаться при рассмотрении процесса
генерации промежуточного представления.
Вариант представления
структуры процедуры в данном тексте не
рассматривается. Его построение
предлагается в качестве самостоятельного
задания.

Разработка структур данных по абстрактным описаниям
Рассмотренные
абстрактные представления с применением
диаграмм Вирта позволяют легко перейти
к описанию структур данных на языке
программирования. В качестве языка,
иллюстрирующего особенности перехода,
используется C. Методика
достаточно проста: все альтернативы
записываются в виде объединения с
предварительным заданием ключа выбора
(вариантная запись в языке программирования
Pascal), рекурсивные вхождения
задаются через указатели. Тогда,
приведенное на рис. 11.1 назначение, будет представлено
следующей структурой.

struct application { // Назначение переменной.
apValue appl; // Параметр, задающий тип текущей альтернативы.
union { // Назначения, используемые в качестве альтернатив.
varTyp var; // Назначение имени - переменная.
typTyp typ; // Назначение имени - тип.
labTyp lab; // Назначение имени - метка.
procTyp proc; // Назначение имени - процедура.
} val;
};
Естественно, что тип
переменной задающей текущее назначение
имени должен быть описан заранее. Для
этого, например, можно использовать
перечислимый тип:
typedef enum {VAR,TYP,LAB,PROC} apValue;
Следует
отметить, приведенный способ задания
структуры не является единственным.
Его недостатком является то, что
непосредственно размещение всех
альтернатив в объединении ведет к
неэкономному выделению памяти по размеру
самой большой структуры, расположенной
внутри этого объединения. Поэтому можно
воспользоваться набором указателей на
выделяемые структуры, вместо самих
структур, что, правда, ведет к другим
недостаткам.
struct application { // Назначение переменной.
apValue appl; // Параметр, задающий тип текущей альтернативы.
union { // Назначения, используемые в качестве альтернатив.
varTyp *var; // Назначение имени - переменная.
typTyp *typ; // Назначение имени - тип.
labTyp *lab; // Назначение имени - метка.
procTyp *proc; // Назначение имени - процедура.
} val;
};
Выбор
конкретного варианта реализации зависит
от множества факторов и определяется
индивидуально в каждом конкретном
случае. Например, можно вообще отказаться
от явной типизации и определять тип
альтернативы в ходе выполнения программы.
Тогда, набор альтернатив будет представлен
следующим образом:
struct application { // Назначение переменной.
apValue appl; // Параметр, задающий тип текущей альтернативы.
void *val; // Назначения, используемые в качестве альтернатив.
};
Аналогичные модификации
возможны и для других структур данных,
что в дальнейшем больше не обсуждается.
Описание
типа данных сопровождается аналогичным
представлением альтернативы. Кроме
этого добавлена переменная, задающая
размер типа в единицах измерения памяти
(в данном случае предполагается, что
это будет байт).
// Перечислимый тип, задающий разновидности типов данных
typedef enum {SCALAR, VECTOR, STRUCT, UNION} typValue;
struct typTyp {
int size;
typValue typ;
union {
scalTyp scal;
vecTyp vec;
strTyp str;
uniTyp uni;
} val;
};
Ниже
приводятся структуры данных, используемые
для представления отдельных типов.
Следует отметить, что разновидности
скалярного типа задаются посредством
перечисления. Предполагается, что
информация о размере скаляров будет
находиться непосредственно в самой
программе.
// Перечислимый тип, определяющий разновидности скалярного типа
typedef enum {INT, CHAR, FLOAT} scalType;
Информация
о векторном типе хранится в структуре
vecTyp.
Связь с типом, определяющим элементы
вектора, осуществляется через указатель.
Таким образом осуществляется реализация
иерархических и рекурсивных соединений.
struct vecTyp {
int len; // Длина вектора, задается целым положительным числом
struct typTyp *typ; // Указатель на тип элементов вектора
};
Для
организации списка элементов структуры
можно использовать разнообразные
контейнеры. Для иллюстрации выбран
простейший подход, когда в структуре
хранится указатель на первый элемент
однонаправленного линейного списка, а
каждый из элементов содержит указатель
на следующий элемент. Аналогичным
образом осуществляется и организация
данных для объединений.
struct strTyp { // Описание структурного типа
struct strElem *elem; // Указатель на первый элемент списка
};
struct strElem { // Элемент структуры
typTyp *typ; // Тип элемента структуры
int addr; // Смещение элемента относительно начала структуры
struct strElem *next; // Указатель на следующий элемент структуры
};
struct uniTyp { // Описание объединения
struct uniElem *elem; // Указатель на первый элемент списка
};
struct uniElem { // Элемент объединения
typTyp *typ; // Тип элемента объединения
struct uniElem *next; // Указатель на следующий элемент объединения
};
Аналогичным
образом осуществляется формирование
структур данных и для других программных
объектов, что предлагается для
самостоятельного изучения.
Обработка элемента таблицы имен
Обработка элемента таблицы
имен осуществляется в соответствии с
его внутренней структурой. В начале
анализируется назначение имени. После
этого выбирается группа (переменная,
тип и т.д.) и продолжается дальнейший
анализ в соответствии со структурой
выбранного назначения. Такую обработку
легко организовать с использованием
условных операторов или переключателей
(switch в языке C
или case в языке Pascal).
Организация элемента таблицы имен в DPL
Язык DPL
достаточно прост. В нем имеется только
один тип назначения имени – переменная.
Проста и организация типов данных. Все
это позволяет легко упростить структуру
назначения и тем самым упростить ее
организацию (рис. 11.11). При таком упрощении
предполагается, что скалярные и векторные
переменные отличаются друг от друга по
значению параметра, определяющего
длину. Для скаляров его значение равно
0, а для векторов может принимать значение
от 1 и выше. В соответствии с представленной
схемой формируется и структура данных
для конкретного языка программирования:
typedef enum {INTTYPE, FLOATTYPE} scaltype;
struct application {
struct scalTyp typ; // скалярный тип
int len; // длинна вектора 1 и более – вектор, 0-скаляр
int addr; // адрес в физической памяти
// (память только статическая)
};
Элемент
таблицы имен содержит имя и назначение.
В данном случае полагаем, что имя доступно
через указатель на соответствующую
строку символов:
Struct element {
char *name;
struct application appl;
… // Прочие возможные параметры.
};
Построение таблицы имен
Построение
таблицы имен осуществляется в ходе
синтаксического анализа при обработке
описаний новых переменных:
Ищется имя в
таблице имен, соответствующее текущей
лексеме, определяющей идентификатор.
Если такое
имя найдено, то выдается сообщение об
ошибке: "Повторное определение
имени", в противном случае имя
заносится в таблицу и осуществляется
формирование значений атрибутов
очередного элемента таблицы.
Использование
таблицы имен осуществляется с применением
функций, рассмотренных при выполнении
лабораторной работы №1:
нахождение
имени в таблице по заданному значению
(find);
включение
имени в заданное место таблицы (incl);
удаление
элемента из таблицы и ее очистка по
завершении работы с таблицей имен (del,
clear).
Использование таблицы имен при выполнении операторов программы
После того,
как, для вновь введенного имени,
определяются значения всех атрибутов,
задающих контекст, становится возможным
его использование при дальнейшем анализе
программы. Это использование происходит
в те моменты, когда имя вновь встречается
в тексте программы. В элементарном
случае использование контекста имени
достаточно просто:
осуществляется
поиск имени в таблице имен;
если оно
найдено, то сопоставляются имя, указанное
в таблице и текущая его семантика.
при отсутствии
противоречий происходит дальнейший
разбор и использование имени в контексте
программы.
наличие
противоречий ведет к формированию
сообщений об ошибке.
если же имя
не найдено в таблице, то формируется
сообщение об использовании неописанного
имени.
В языках со сложной семантической
организацией (PL/1 и т.д.) алгоритмы
формирования и использования таблиц
имен сложнее. Имена могут использоваться
до их описания за счет параметров,
устанавливаемых по умолчанию. Эти
параметры могут переопределяться.
Переопределения могут встречаться не
только во внутренних, но и внешних
модулях программы.
Наличие меток без их
предварительного описания (в Паскале,
например, есть предварительное описание),
тоже ведет к более сложным алгоритмам
семантической обработки. Имя метки
заносится в таблицу при первой встрече
независимо от того, где она встретится:
в операторе перехода на указанную метку
или в метке перед оператором. В первом
случае контекст имени до конца не
определен, так как неизвестна точка
перехода. Во втором случае контекст
определяется сразу. Использование
контекста метки выявляется из ее
начального определения. Если в начале
метка появилась вперед оператора, то
весь ее контекст определен. Запрещается
повторное появление метки в данном
назначении. Однако, появление операторов
перехода с данной меткой вполне
естественно. Если же метка появилась в
начале оператора перехода, то в дальнейшем
она обязана, хотя бы один раз, появится
и перед оператором, чтобы ее контекст
был доопределен.
Синтаксически управляемый перевод
Выполнение
семантического анализа в каждой из трех
его фаз непосредственно связано с
проводимым разбором. То есть, каждый
вид семантического анализа жестко
привязан к синтаксической структуре.
Формальное описание языка и выстраиваемое
дерево разбора служат подобием скелета,
который обрастает мышцами, обеспечивающими
выполнение полезных действий. Такой
подход является логически обоснованным
и подкрепляется причинно-следственными
связями:
в начале мы
убеждаемся в синтаксической корректности
цепочки, определяющей различные
программные объекты и, на основе этого,
создаем синтаксическую структуру
программы, состоящую из семантически
неопределенных объектов;
построив
синтаксически правильные программные
объекты, можно осуществлять их
семантическое наполнение путем создания
объектной модели программы или ее
промежуточного представления;
дальнейшие
действия, связанные с генерацией кода
объектной машины уже не связаны с
синтаксической структурой, а используют
только построенную объектную модель
или промежуточное представление.
Синтаксически управляемый
перевод описывается с использованием
атрибутных грамматик [Льюис]. В этих
грамматиках, наряду с терминалами и
нетерминалами, используются порождающие
символы, с каждым из которых связан
набор определенных действий. Эти символы
и определяют семантическую обработку
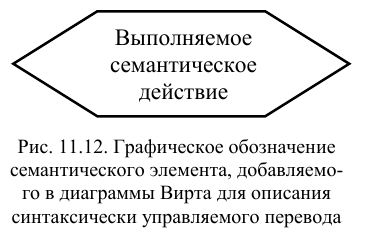
данных в трансляторе. Аналогичные
понятия можно ввести и в диаграммы
Вирта, обозначив порождающие элементы
специальными графическими примитивами,
например, шестиугольниками (рис. 11.12), внутри которых можно
записывать ссылку на семантическое
действие, или само действие.
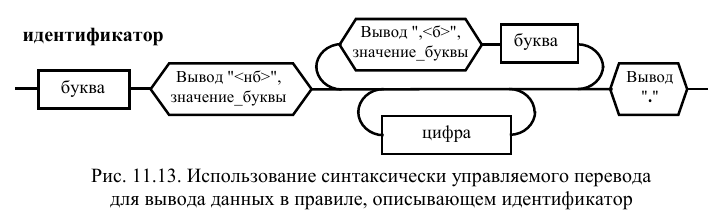
В качестве
примера простейшего синтаксически
управляемого перевода рассмотрим выдачу
данных в выходной поток, привязанную к
правилу, определяющему идентификатор
как совокупность букв и цифр, начинающихся
с буквы. Правило, описывающее идентификатор,
с включенными в него семантическими
элементами, приведено на рис. 11.13. Как видно из рисунка, после
распознавания первой буквы осуществляется
вывод текста: "<нб>" и значения
этой буквы, после чего выводится запятая.
Каждая последующая буква сопровождается
выводом текста ",<б>" и значением
буквы. Распознавание цифр не сопровождается
семантическими действиями. По окончании
обработки правила выводится точка.
Использование данного правила позволяет
порождать на выходе разнообразные
цепочки, вид которых связан с входной.
При этом отсутствие семантических
действий для цифр обеспечивает их
фильтрацию, что, для различных входных
цепочек, позволяет порождать одинаковые
выходные данные. Ниже приводится
несколько примеров выводимых данных
для различных входных цепочек:
-
|
Входная цепочка
|
Выходная цепочка
|
|
A23BC2
|
<нб>A,<б>B,<б>C.
|
|
ABC
|
<нб>A,<б>B,<б>C.
|
|
D37564
|
<нб>D.
|
Использование синтаксически управляемого перевода при построении таблиц имен
Действия, обеспечивающие
добавление нового элемента в таблицу
имен, непосредственно связаны с теми
правилами программы, которые обеспечивают
распознавание имен. Например, для
переменных такими правилами являются
правила, задающие описания, для меток
- правила, определяющие операторы
перехода и помеченные операторы, для
типов - описания типов, процедур - описания
процедур и прототипов и т.д. Для того,
чтобы добавить в программу разрабатываемого
транслятора фрагменты кода, осуществляющие
построение таблиц имен, необходимо
поступить следующим образом:
найти правила, задающие
описания имен различного назначения
и добавить к ним, в соответствующих
точках, семантические элементы,
осуществляющие формирование требуемого
контекста;
аналогичные вставки
осуществляются и в код программы,
определяющий правила синтаксического
анализатора.
Данная процедура не является
формальной и зависит от сложности языка
программирования, для которого
разрабатывается транслятор. Кроме этого
необходимо учитывать и семантику этого
исполнения, которая в разных языках
отличается даже для подобных правил.
Необходимо также учитывать и особенности
синтаксической структуры, которые
по-разному определяют формирование
контекста. В одних случаях, для сохранения
данных необходимо создавать дополнительные
промежуточные структуры, тогда как в
других можно обойтись и без них.
Построение таблицы имен для демонстрационного языка
Отсюда можно скачать исходные тексты распознавателя с добавленной таблицей имен
демонстрационного языка программирования.
В демонстрационном языке
программирования новые имена впервые
вводятся в программу только в описаниях.
Поэтому, соответствующую семантическую
обработку необходимо добавить в правило,
определяющее описание. Исходное правило
представлено на рис. 11.14а.
Его вид после добавления семантических
элементов представлен на рис. 11.14б.
Следует отметить, что появление
семантических вставок меняет количество
терминалов и нетерминалов в правиле,
так как, даже после одного и того же
символа возможны различные семантические
вставки. Однако, организация связей
остается неизменной. Поэтому не надо
менять код, определяющий реализацию
правил. На данном рисунке семантические
вставки пронумерованы и связаны со
следующими действиями:
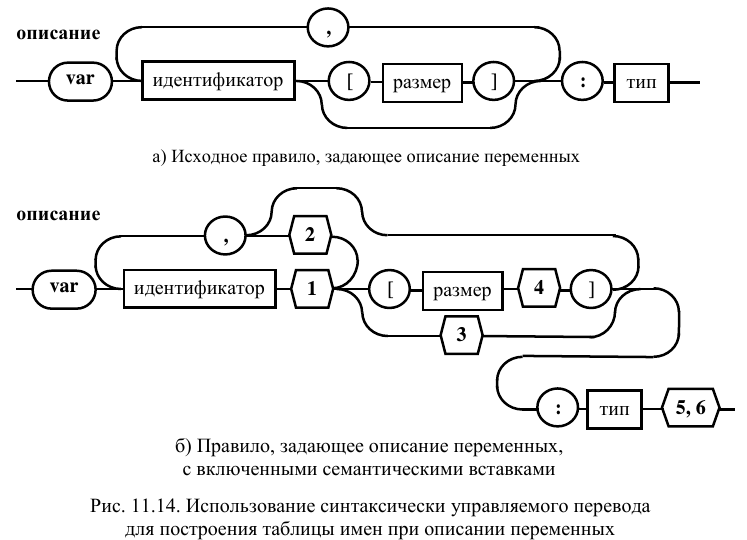
Поиск в таблице имен.
Если имя отсутствует,
то: оно включается в таблицу. Кроме
этого, указатель на данный элемент в
таблице фиксируется во временном
списке, предназначенном для хранения
всех имен данного описания. Это
необходимо сделать для того, чтобы в
дальнейшем доопределить семантику
имен, так как структура правила не
позволяет сразу определить тип
переменной и занимаемый ею объем
памяти.
Если же переменная с
данным именем уже имеется в таблице,
то фиксируется ошибка и выдается
сообщение о повторном описании имени
переменной. Дальнейший разбор не
проводится или осуществляется
нейтрализация ошибки.
Установка признака
скаляра для текущей переменной списка.
Параметр длины первоначально
устанавливается в нулевое значение.
То есть, предполагается, что описываемая
переменная является скалярной.
Установка признака
скаляра для последней переменной
списка. Параметр длины первоначально
устанавливается в нулевое значение.
Данное действие эквивалентно действию,
описанному в пункте 3, но выполняется
по другой условной ветви. Если бы объем
вычислений в этих семантических
элементах был большим, то можно было
бы реализовать отдельную функцию,
вызываемую в нужных точках.
Установка длины вектора.
При наличии описателя размерности
сформированного целое число определяет
длину вектора. Его значение, преобразованное
сканером во внутреннее представление,
заносится в параметр, определяющий
длину векторной переменной.
Фиксация типа и
распределение памяти для описанных
целочисленных переменных. После
того, как определен целочисленный тип
переменных, имеются все данные, чтобы
завершить формирование параметров
переменных. Для этого осуществляется
перебор элементов временного списка,
в ходе которого устанавливается целый
тип и вычисляется размещение в памяти,
зависящее не только от типа, но и
размерности.
Фиксация типа и
распределение памяти для описанных
действительных переменных. После
того, как определен действительный тип
переменных, имеются все данные, чтобы
завершить формирование параметров
переменных. Для этого осуществляется
перебор элементов временного списка,
в ходе которого устанавливается действительный
тип и вычисляется размещение в памяти,
зависящее не только от типа, но и
размерности.
Следует отметить,
что даже для этого правила могут быть
другие варианты обработки, обеспечивающие
построение эквивалентной таблицы имен.
Можно осуществить дополнительную
оптимизацию, сокращающую код, использовать
вспомогательные процедуры и функции и
т.д.
Программная реализация построения таблицы имен для демонстрационного языка
int decl() {
struct node* varyable[256]; // Временный список на заносимые переменные.
// Реализован без дополнительных проверок на переполнение.
int i = -1; // указатель на первый элемент массива varyable
_0:
if(lc==KWVAR) {nxl(); goto _1;}
return 0; // Не описание
_1:
if(lc==ID) { // Идентификатор описываемой переменной
if(!find(lv)) { // При отсутствии описания переменной формируем новое
varyable[++i] = incl(lv);
} else {
er(19); return 0; // Ошибка: повторное определение имени
}
nxl(); goto _2;
}
er(5); return 0; // Ошибка: недопустима лексема внутри описания
_2:
if(lc==LSB) {nxl(); goto _3;}
if(lc==CL) {
// Определяется скалярная переменная. Размер = 0
varyable[i]->val.appl.len = 0;
nxl(); goto _1;
}
if(lc==DVT) { // Определяется скалярная переменная. Размер = 0
varyable[i]->val.appl.len = 0;
nxl(); goto _6;
}
er(5); return 0; // Ошибка: недопустима лексема внутри описания
_3:
if(lc==INT) {
// Фиксируется длина для массива
varyable[i]->val.appl.len = unum;
nxl(); goto _4;
}
er(5); return 0; // Ошибка: недопустима лексема внутри описания
_4:
if(lc==RSB) {nxl(); goto _5;}
er(5); return 0; // Ошибка: недопустима лексема внутри описания
_5:
if(lc==CL) {nxl(); goto _1;}
if(lc==DVT) {nxl(); goto _6;}
er(5); return 0; // Ошибка: недопустима лексема внутри описания
_6:
if(lc==KWINT) { // Все переменные целого типа
// Размер целого равен два байта (задан явно)
int j; // Индекс для перебора всех переменных с данным типом
for(j = 0; j <= i; ++j) {
varyable[j]->val.appl.typ = INTTYP;
varyable[j]->val.appl.addr = memAddr;
if(varyable[j]->val.appl.len == 0)
memAddr += 2;
else
memAddr += 2*varyable[j]->val.appl.len;
}
nxl(); goto _end;
}
if(lc==KWFLOAT) { // Все переменные действительного типа
// Размер действительного равен четыре байта (задан явно)
int j; // индекс для перебора всех переменных с данным типом
for(j = 0; j <= i; ++j) {
varyable[j]->val.appl.typ = FLOATTYP;
varyable[j]->val.appl.addr = memAddr;
if(varyable[j]->val.appl.len == 0)
memAddr += 4;
else
memAddr += 4*varyable[j]->val.appl.len;
}
nxl(); goto _end;
}
er(5); return 0; // Ошибка: недопустима лексема внутри описания
_end:
return 1;
}
Использование синтаксически управляемого перевода при работе с таблицей имен
После того, как используемое
имя занесено в таблицу и для него
сформирован контекст, становится
возможными использование данного имени
в различных операциях, выполняемых
программой. Следовательно, в ходе
синтаксического анализа, можно
использовать данные, зафиксированные
в таблице, для построения объектной
модели или промежуточного представления.
Это использование происходит в те
моменты, когда данное имя повторно
встречается в тексте программы. В
элементарном случае использование
контекста имени достаточно просто:
Осуществляется поиск
имени в таблице имен.
Если имя найдено, то
сопоставляются назначение имени,
указанное в таблице и его текущий
контекст.
При отсутствии противоречий
происходит дальнейший разбор и
использование имени в соответствии с
семантикой обрабатываемого фрагмента
программы.
Наличие противоречий
между назначением и текущим контекстом
ведет к семантической ошибке. Необходимо
обработать ошибку и сформировать
соответствующее сообщение.
Если же имя не найдено,
то формируется сообщение об ошибочном
использовании неописанного имени. В
соответствии с избранным методом
обработки ошибки осуществляется либо
дальнейший анализ, либо его завершение.
Семантические элементы,
осуществляющие подобную обработку,
обычно вставляются в те места диаграмм
Вирта, в которых определяются имена
посредством идентификаторов.
В языках с более сложной
семантической структурой (таких, как
PL/1, Fortran и
т.д.) алгоритмы формирования и использования
таблиц имен являются более сложными.
Они могут содержать формирование
назначения имени по умолчанию, если оно
в первый раз встретилось не в объявлении,
а в операторах. Если после этого имя
встречается в объявлении, то его
назначение переопределяется. Все это
усложняет процесс трансляции, который
необходимо, в таких случаях осуществлять
за большее число проходов. На первых
проходах осуществляется построение
таблицы имен, определение и переопределение
назначений этих имен. Только на следующих
проходах таблица имен используется для
построения объектной модели языка или
промежуточного представления, по которым
в дальнейшем осуществляется генерация
кода. В языках со строгой типизацией и
предварительным описанием данных
построение и использование таблицы
имен могут выполняться на одном проходе.
Свои особенности также
проявляются и при использовании меток.
В языках с предварительным описанием
меток (таких как Pascal) метки
заносятся в таблицу до анализа текста
программы. Транслятору остается только
следить за тем, чтобы в программе не
использовались другие метки, и не было
повторной установки перед операторами
объявленных меток. Предварительное
объявление меток позволяет заранее
сформировать программные объекты,
отвечающие за их корректное использование.
Использование меток без
предварительного описания несколько
усложняет алгоритм их использования.
В этом случае, имя метки заносится в
таблицу при ее первой встрече, независимо
от того, где она встретилась: в операторе
перехода или в заданной позиции перед
оператором. Если метка впервые встретилась
в операторе перехода, ее контекст до
конца не определен, так как неизвестна
позиция, на которую осуществляется
переход. Вместе с тем, если имя метки не
противоречит общему контексту программы,
заносится в таблицу имен. После этого
соответствующий элемент таблицы имен
будет иметь такую же организацию, как
и элемент, который формируется по
предварительному описанию метки. После
этого в назначении данного имени
необходимо учесть, что оператор перехода
до конца не определен. Учесть это можно,
например, фиксацией указателя на
формируемую команду перехода или ее
операнд, определяющий адрес перехода.
Этот адрес будет доопределен, когда в
тексте программы встретится метка пред
оператором. Его значение будет равно
значению параметра, определяющего
местоположение метки.
Если же в программе, до
появления самой метки, будут встречаться
другие операторы перехода, то в назначение
имени метки, расположенном в таблице
имен, необходимо добавлять указатели
на все встречающиеся команды перехода
или их операнды задающие данные адреса.
Тогда, появление метки приведет к
доопределению целого списка команд
перехода, встретившихся до этой метки.
Список отложенных операторов перехода
после этого очищается.
Если же метка встретилась до
операторов перехода, в таблицу сразу
заносится имя, один из параметров
которого определяет местоположение
метки. Все операторы перехода, появляющиеся
после метки, могут быть сразу определены,
что отменяет их хранение в списке
отложенных операторов.
Следует отметить, что семантика
и места использования меток значительно
отличаются от семантики и мест
использования других программных
объектов. Это ведет к тому, что во многих
языках программирования (например, С и
C++) имена меток могут
совпадать с именами других программных
объектов (в C и C++
это касается не только имен меток, но и
функций, а также ряда других имен). Все
это может привести к реализации, когда
в программе существует не одна, а
несколько таблиц имен: одна - для
переменных, другая - для меток и т.д.
Использование одной или нескольких
таблиц имен для различных программных
зависит, в основном, от семантики языка
программирования и технических решений,
принимаемых разработчиком транслятора.
Можно, например, иметь одну таблицу
имен, но для каждого имени хранить список
одновременно существующих его назначений.
Использование синтаксически управляемого перевода для работы с таблицей имен в трансляторе с демонстрационного языка
В демонстрационном языке
программирования существует только
одно правило, задающее использование
имени в программе. Это правило, описывающее
переменную (рис. 11.15а). Добавление
семантического элемента слегка изменяет
его вид (рис. 11.15б). Сами же действия
дополнительной вставки 1 описываются
следующим образом:
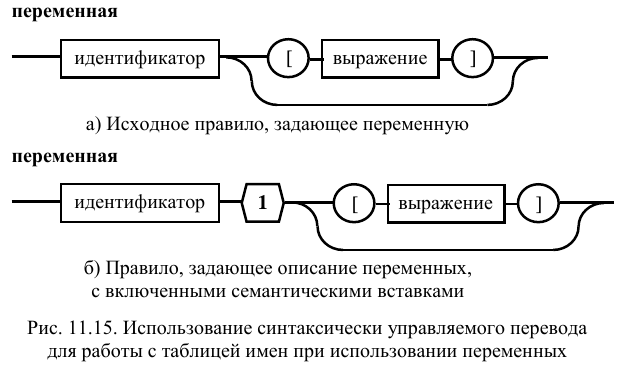
Анализ нахождения имени
переменной в таблице. Если имя,
совпадающее с анализируем идентификатором
находится в таблице, то возвращается
указатель на его назначение (или на
весь элемент таблицы). Если же имя не
найдено, то формируется сообщение о
появлении в программе имени с неизвестным
контекстом, которое предварительно не
определено, и производится обработка
ошибки.
Необходимо обратить внимание
на отсутствие семантических вставок,
анализирующих корректность использования
переменных. В частности, нет проверки
на использование скалярной переменной
с квадратными скобками или векторной
переменной без квадратных скобок. В
принципе, такие проверки легко можно
было бы добавить уже сейчас, но будем
считать, что семантика языка в этом
вопросе пока до конца не определена. То есть, в дальнейшем мы вполне можем
допустить использование только имени
векторной переменной в векторных
операциях (как это сделано в PL/1)
или выбор бита из скалярной переменной
по указанному индексу. Кроме того, что
данные действия определяются семантикой
языка, их реализацию можно рассматривать
тогда, когда идет вопрос о генерации
кода и осуществляется комплексная
проверка семантики. Это еще одна причина
отложить решение данного вопроса.
Программная реализация фрагмента работы с таблицей имен
Ниже приводится исходный текст функции, осуществляющей работу с таблицей имен при разборе правила, описывающего переменную.
int varying() {
_0:
if(lc==ID) {
// имя переменной д.б. в таблице имен
if(find(lv)) {
// Использование элемента таблицы имен.
// Должно добавиться при формировании объектной модели
} else {
er(20); return 0; // Имя предварительно не определено
}
nxl(); goto _1;
}
return 0; // Это не переменная. Выход без ошибки на анализ другой версии.
_1:
if(lc==LSB) {nxl(); goto _2;}
goto _end;
_2:
if(expr()) {goto _3;}
er(15); return 0; // Ошибка: в этом месте допустимо только выражение
_3:
if(lc==RSB) {nxl(); goto _end;}
er(15); return 0; // Ошибка: допустима только закрывающаяся квадратная скобка.
_end:
return 1; // Правило успешно распознано.
}
Контрольные вопросы и задания
-
Как используется синтаксически управляемый перевод при построении таблицы имен?
-
Как используется синтаксически управляемый перевод при работе с таблицей имен?
-
Какие семантические действия должны выполняться, на ваш взгляд, при объявлении в программе метки?
-
Какие семантические действия должны выполняться, на ваш взгляд, при появлении в программе оператора безусловного перехода на метку?
-
Добавьте в программный модуль распознавателя дополнительные вставки, реализующие функции, обеспечивающие работу с таблицей имен.
[
содержание
| предыдущая тема
| следующая тема
]
|