Что является неправильным в OLE
Рассказ посвященного лица
Перевод А. И. Легалова
Англоязычный оригинал находится на сервере компании
Reliable Software
Вы могли слышать или
читать критические мнения
относительно OLE. Программисты
обычно жалуются на сложность
системы подсчета ссылок и
недостатосную поддержку
наследования. Microsoft обожествляет
этот счетчик, говоря, что нет
никакого другого способа, и что
этот способ является для вас
наилучшим1.
Интерфейсы, как сказано, должно
быть ссылочно подсчитаны (refcounted), и
имеется мудрый, рубильник
обеспечивающий соединение (агрегацию)
частей (нежно называемый
ухудшением (aggravation) OLE
программистами), который
обеспечивает те же самые
функциональные возможности, что и
наследование. Может быть они правы,
и проблема взаимодействия с
объектами, загружаемыми во время
выполнения настолько сложна, что
просто не имеется более лучшего
способа? С другой стороны, возможно,
что OLE имеет фатальный дефект,
который только обостряется во всех
других местах.
| Фатальный дефект
проекта OLE - требование того,
чтобы была возможность
добраться от любого интерфейса
до любого другого интерфейса. |
Технически это интерфейсное
прыгание сделано за счет того, что
каждый интерфейс наследует от
матери всех интерфейсов IUnknown. IUnknown
имеет фатальный метод QueryInterface,
который, как предполагается,
возвращает любой интерфейс,
обеспечиваемый текущим объектом.
Это единственное предположение
препятствует наличию любой
возможности простой реализации
наследования. Позвольте мне
объясняют почему.
Предположим, что Вы имеете объект
FooObj с интерфейсом IFoo. Эта ситуация
легко моделируется в C++ при наличии
абстрактного класса (все методы -
чистые виртуальные) IFoo и
конкретного класс FooObj, который
наследуется из IFoo и реализует все
его методы.
Теперь Вам вдруг захотелось
расширить этот объект, добавляя
поддержку для другого интерфейса
IBar. В C++ это тривиально, Вы только
определяете класс FooBarObj, который
наследует от FooObj и IBar. Этот новый
класс поддерживает интерфейс IFoo
вместе с его реализацией через
наследование из FooObj. Он также
поддерживает интерфейс IBar и
обеспечивает реализацию методов IBar.
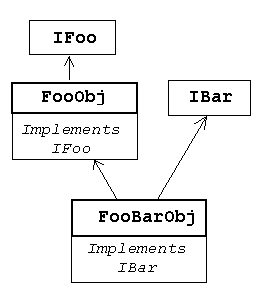
Любой, кто знает C++, может сделать
это с закрытыми глазами. Так, почему
же Вы не можете сделать то же самое
в OLE? Здесь проявляется Изъян. Вы
должны быть способны получить
интерфейс IBar из интерфейса IFoo,
используя его QueryInterface. Но,
подождите минуту, объект FooObj,
который обеспечивает реализацию
всех методов IFoo, включая QueryInterface, не
имеет никаких сведений
относительно IBar! Невозможно было
даже представить наличие IBar. Так,
как же в этой ситуации обеспечить
доступ к IBar?
Хороший вопрос. Я не собираюсь
входить в кровавые подробности
агрегационной рубки, которая, как
предполагается, решает эту
проблему. Накладываемые
ограничения и пороки начального
проекта, действительно,
изобретательно, рубят. Так имеется
ли лучший проект? Читайте дальше...
Можете ли Вы отметить
случай, когда были вынуждены
проводить различия между объектом,
который реализует интерфейсы и
интерфейсами непосредственно? Это
два полностью различных понятия. Вы
не можете объяснить что-нибудь в OLE
без того, чтобы не говорить об
объектах, иногда называемых
компонентами. Интерфейсы важны, но
объекты еще более важны. Когда Вы
можете получить один интерфейс от
другого? Когда они совместно
используют один и тот же основной
объект. Вы можете изменять
состояние объекта, используя один
интерфейс и затем исследовать это
состояние через другой интерфейс.
Очевидно, что это тот же самый
объект! В моем примере я описал два
интерфейса, IFoo и IBar, и два объекта (или
класса объектов), FooObject и FooBarObject.
Фактически, любой, кто реализует
интерфейсы (используя C++, C, или Basic)
имеет дело с объектами. Однако, эта
очень важная абстракция полностью
отсутствует с точки зрения клиента
OLE. Все, что клиент видит - это
интерфейсы. Основной объект
подобен призраку.
Но это не призрак. Он физически
представлен в адресном
пространстве вашей программы, или
непосредственно, или как заглушка
пересылки. Так, почему скрывают это?
Действительно, разве OLE не было бы
более простым с явным понятием
объекта? Давайте посмотрим, как это
работало бы.
Клиент этого "интеллектуального
OLE" вызвал бы CoCreateInstance или ClassFactory::
CreateInstance, чтобы получить указатель
на объект (а не на интерфейс!).
Используя этот указатель, клиент
вызвал бы QueryInterface, чтобы получить
интерфейс. Если бы клиент хотел
получить другой интерфейс, он или
она сделали бы другое обращение
QueryInterface через объект, а не через
интерфейс. Вы не могли бы получать
интерфейс из другого интерфейса.
Только объект обладал бы
способностью распределять
интерфейсы. Bye, bye IUnknown!
Позвольте мне показать Вам
некоторый гипотетический код в
этом новом "интеллектуальное OLE".
CoObject * obj CoCreateInstance (CLSID_FooBarObject);
IFoo * foo = obj->QueryInterface (IID_FOO);
foo->FooMethod ();
IBar * bar = obj->QueryInterface (IID_BAR);
bar->BarMethod ();
delete obj;
|
Я преднамеренно опустил всю
проверку ошибок и подсчет ссылок.
Фактически, я не написал бы код,
подобный этому, в серьезном
приложении, я использовал бы
интеллектуальные указатели и
исключения. Но обратете внимание на
одну вещь, в "интеллектуальном OLE"
наследование столь же просто как и
в C++. Здесь не имеется никакого
способа перейти от интерфейса к
интерфейсу и нет никакого IUnknown.
Расширение FooObject, добавлением IBar
требует не больше работы чем
создание FooBarObject, наследующего от
FooObject и IBar, реализующего методы IBar и
переписывание метода QueryInterface CoObject.
Я полагаю, что все "интеллектуальное
OLE" объекты наследуют от
абстрактного класса CoObject и
переопределяют его метод QueryInterface (это
очень отличается от наличия всех
интерфейсов, наследующих от IUnknown!).
Что сказать о подсчете ссылок?
Вполне очевидно, что имеются очень
немного потребностей в подсчете
ссылок (refcounting), пока Вы
соглашаетесь не уничтожать объект,
в то время пока Вы используете его
интерфейсы. Это не такое большое
дело. Мы делаем это все время, когда
используем методы в C++. Мы не думаем
о том, что это особенно жесткое
требование: не уничтожить объект, в
то время как мы используем его
методы. Если мы должны следовать за
текущей моделью OLE везде, мы должны
требовать, чтобы клиент получал
счетчик ссылок любого метода,
который он, или она планируют
использовать, а затем освобождать
его после вызова? Это было бы
абсурдно, не так ли?
Так, почему же OLE так придирчиво
считает ссылки? Простое объяснение:
потому что это скрывает объект от
клиента. OLE-объект создается неявно,
когда Вы получаете его первый
интерфейс, и разрушается неявно,
когда Вы освобождаете его
последний интерфейс. Вы видите, что
OLE делает для Вас большую пользу,
скрывая эту бухалтерию от Вас. Так
ли это? Забавный вопрос.
| Давным
давно, когда
машинные языки были все еще в
их младенчестве, мастера C,
пробовали реализовать стек.
Они сделали открытие, что всем
клиентам нуждающимся в стеке
нужны были две функции,
втолкнуть (push) и вытолкнуть (pop).
Они также поняли (реализовали),
что они должны будут выделить
некоторую память, чтобы
хранить данные стека и, так как
они были опрятные программисты,
они будут должны были
освободить их, когда клиент был
обслужен. Но как они узнали бы,
когда клиент был обслужен?
Совершенно очевидно, что
клиент был обслужен, когда он
или она не должны были бы
большк выполнять вызовы push или
pop. Как только мастера C поняли
это, остаток был прост. Стек был
создан и память распределялась,
когда клиент впервые
запрашивал push. Он мог затем
вызывать push со специальным
параметром, чтобы получить
соответствующее pop. Фактически,
используя эту схему, он мог
создавать столько push и pop,
сколько он желал. Затем, когда
он был обслужен с заданными push
или pop, он просто освобождал бы
их. Однократное освобождение
всех вталкиваний и
выталкиваний привело бы к
освобождению стека. Эта
гениальная схема чрезвычайно
упрощала программирование,
потому что клиенты не должны
были иметь дело со стеком
непосредственно. Система вела
всю бухгалтерию. Программисты
были в экстазе, и они отдали все
их деньги мастерам C. Между
прочим, новые функции
назывались i_push и i_pop. |
Здесь самая лучшая часть истории.
Вы могли бы подумать: " О, право,
большое дело! Легко придумать эти
идеи теперь, после того, как OLE
находится на рынке для почти
десятилетие". Сообщаю, что
искренне Ваш был тем, кто работал
когда-то в Microsoft. Вскоре, после
выпуска OLE 1.0, я записал эти идеи и
послал ответственным людям. Короче
говоря, идеи были приняты как
допустимые, но отклонены, потому
что уже имелось слишком много кода,
записанного в спецификациях OLE (обычное
дело в Microsoft). Никто из менеджеров не
пожелал рисковать, перепроектируя
OLE.
Итак, теперь мы имеем подсчет
ссылок, агрегацию и все прочее.
Мораль истории:
Нет ничего святого,
что касается OLE. Это может быть
сделано лучше!
|
Но мы все же можем иметь пирог и
есть его? Другими словами, можно
формировать "интеллектуальное OLE"
на вершине "другое OLE"? Ваша
ставка! Идите прямо к следующей
обучающей программе.
1Меня задело за живое
введение к главе по агрегации в
прекрасной (хотя так или иначе
тупой) книге "Внутри COM" Дейла
Роджерсона ("Inside COM" by Dale Rogerson).
Если бы он знал реальную историю, он
не был бы столь непреклонен в его
защите агрегирования.
|